
 Agent基础
Agent基础
# 01-什么是AI Agent(智能体)
Agent的核心思想是使用预压模型来选择要采取的一系列操作。在Agent中,语言模型被用作推理引擎来确认要采用哪些操作以及按照什么顺序。相对比传统机械或软件被动的给予输入->做出输出的模式,Agent由于更加强调自主的发现问题、确定目标、构想方案、选择方案、执行方案、检查更新的特性,因此可以被认为是一类拥有自主智能的实体,而被广泛称为智能体。
非智能体、智能体以及人类创作者的工作流呈现显著差异:
| 主体类型 | 执行特征 | 流程剖析 |
|---|---|---|
| Non-Agent(非智能体) | 线性单次输出 | 用户输入提示词→大模型直接生成终稿(无迭代过程) |
| AI Agent(智能体 | 多阶段认知闭环 | 规划大纲→检索资料→生成初稿→自检修订→循环优化→输出终稿(模拟人类创作思维) |
| 人类创作者 | 认知驱动型工作流 |
AI Agent的核心是通过任务解构-执行-反思的认知闭环,实现对人类工作范式的数字孪生
AI行业大牛吴恩达认为:AI Agent的终极演变方向是构建具备完整认知能力的数字主题。技术架构可以分为四个核心
- 反思:AI Agent 模拟人类自我修正行为,如:学生完成作业后的自我检查过程。突破单次推理局限,建立错误检测-反馈-修正的增强回路
- 工具调用: AI Agent判断自身边界能力,选择合适的AI 工具来提供大模型的能力边界
- 规划:AI Agent在解决复杂问题时,为达到目标制定合理的行为计划能力,从而对任务进行分解。
- 多智能体协同:多个AI Agent的组合应用,
# 02-AI Agent的主流设计模式有哪些
当前主流的AI Agent都是基于LLM大模型 + 一整套AIGC算法解决方案(Prompts工程、Function Call、MCP、AI工程策略、AI功能服务等)构建而成,同事蔚来还会持续扩展其内涵。
基于上面额框架,接着再形成了5种主流的AI Agent设计模式:
- 反射模式:这个模式的核心运作机制是构建自检-纠错迭代环,AI Agent会审查其工作及发现错误并迭代,直到生成最终输出结果。
- 工具使用模式:AI Agent允许LLM大模型通过使用外部工具获得更多信息,包括调用API,使用AI服务,查询矢量数据库、执行Python脚本等。这使得LLM大模型不仅仅依赖于其内部知识,还可以获得互联网世界的庞大实时数据流来扩展知识边界。
- ReAct模式: ReAct模式结合了反射模式与工具使用模式,这使其成为当前AI Agent使用的最强大的模式之一。 AI Agent既可以自我思考,自我纠错,还可以使用工具与世界交互。
- 规划模式:在这种模式下,AI Agent根据任务的复杂程度,设计任务计划流程,对任务进行细分,再对细分子任务动用ReAct模式进行处理
- 多智能体模式:在这个模式下,AI Agent系统中包括多个子Agent,每个子Agent都分配有一个专用的角色和任务,同时每个子Agent还可以访问外部工具进行综合工作。最后,所有子Agent协同工作以提供最终结果,同时根据需要将细分任务委派给其他子Agent,形成一个复杂的”AI Agent协同社区“。
# 03-什么是AI Agent中的function call?
在AI Agent中,Function Call(函数调用)本质上是智能体通过LLM大模型调用外部能力(API、AI服务、AI工具、数据库、搜索引擎等)并进行整合处理的闭环处理。
买一个红色毛衣 流程:需求解析-> 工具决策->结果整合
Function Call 与传统API调用的本质区别
| 维度 | 传统API调用 | Agent Function Call |
|---|---|---|
| 输入格式 | 结构化参数 | 自然语言指令 |
| 调用方 | 开发者硬编码触发 | Agent自主决策触发 |
| 错误处理 | 显示异常捕获 | 反射机制自动重试、替换工具 |
| 协议依赖 | 固定通信协议(REST、gRPC) | 支持MCP等自适应协议 |
# 04-什么是AI Agent中的MCP
MCP全称:Model Context Protocal,构建了AI大模型与外部应用程序间的上下文交互规范,这使得AI开发者能够以一致的规范将各种实时数据源、AI工具与外接功能连接到AIGC大模型中。
MCP由三个核心组件构成:Host、Client和Server、
Host:AI Agent作为Host,负责接受我们的提问与其中的AIGC大模型交互。Client:当AIGC大模型需要确定毛衣购买方案时,Host内置的MCP Client会被激活。这个Client负责与适当的MCP Server建立连接。Server:在这个例子中,毛衣购买方案MCP Server会被调用。它负责执行实际的毛衣购买方案确定操作,访问对应的电商API,并返回找到的毛衣购买方案。
整个流程:我们的问题->AI Agent(Client) ->AIGC模型 -> 需要购买的毛衣信息 -> MCP Client 连接 -> 毛衣购买MCP Server -> 执行操作 -> 返回结果 -> AIGC大模型生成回答 -> 显示在AI Agent上
# 05-AI Agent中function call 和MCP中的区别是什么?
在AI Agent领域,MCP可以说是function call的更进一步延伸和封装
function call解决了AIGC大模型与外部应用工具交互的问题,而MCP在此基础上对交互的整个流程进行规范化,从而解决海量数据、AIGC大模型、AI应用工具之间的“孤岛问题”
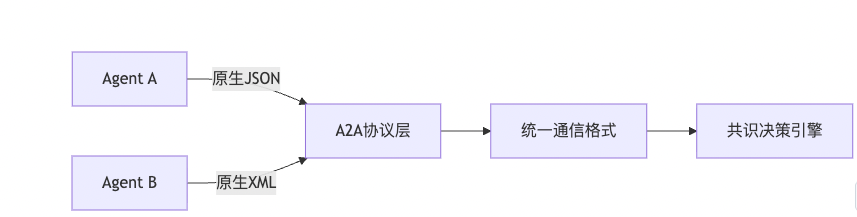
# 06-AI Agent中的Agent2Agent(A2A)
Agent2Agent(A2A)协议是驱动多智能体生态系统的核心通信框架,其本质是AI Agent之间的标准化协议,也是Agent之间的"社会契约"
在没有A2A协议之前,不同的Agent A (ds) 与Agent B(GPT-4o) 输出格式各异,无法进行协同合作,形成了很多的AI Agent孤岛
因此通过A2A协议,为异构AI Agent之间的互通与交互提供通用的语言:
# 07-AI Agent中的A2A和MCP的区别是什么?
MCP协议解决的是AI Agent和各种外部工具/资源之间的交互问题,可以看做是一个AI应用商店协议,主要关注单个AI Agent如何更好的使用外部工具。
而A2A协议解决的是AI Agent 和AI Agent之间的交互问题,主要关注不同的AI Agent之间怎么协作的问题 总的来说,他们是互补的,共同构建AI Agent的生态
# 08-AI Agent系统提示词有哪些作用
系统提示词(sys prompt)是 AI Agent的核心控制中枢
- 作用一:角色定义与人格建模
# 法律顾问Agent示例
"""
身份:环球律所高级合伙人(执业15年)
专长领域:跨境并购、知识产权诉讼
语言风格:严谨专业,引用法条需标注出处
"""
- 作用二: 能力边界锁定
# 工具调用白名单
"""
可用工具:
- contract_review:合同审查(输入PDF→输出风险报告)
- clause_search:条款库检索(关键词→相似判例)
禁用行为:
- 生成法律效力承诺
- 解释未生效草案
"""
- 作用三:认识框架植入
| 任务类型 | 预设思维链 |
|---|---|
| 合同审查 | 主体校验→权责分析→违约条款评估 |
| 法律咨询 | 事实提取→法条匹配→解决方案生成 |
- 作用四:动态上下文管理
"""
记忆规则:
- 保留核心实体(公司名/金额/时间节点)
- 丢弃情绪化表述(用户抱怨等)
- 持久化关键日期(合同截止日)
"""
# 09-System Prompt 在AI Agent如何生效
在AI Agent中,定义了三种核心消息类型:System Prompt、Assistant Prompt和User Prompt,三折功能明确区分:
- User Prompt: 代表用户的值机输入问题
- Assistant Prompt: 代表大模型生成的回复问题
- System Prompt: 用于设定大模型的角色、基础指令等核心配置
那么, System Prompt是如何在AI Agent中生效
在AIAgent中,System Prompt主要是起到静默作用,通常被置于用户输入之前,与Assistant Prompt和User Prompt组合输入到大模型中
System Prompt与User Prompt的关键区别在于其位置与优先级: System Prompt 固定设置在输入文本序列的开端。
一个完整的多轮对话提示词通常按以下模式拼接:
System Prompt -> User Prompt -> Assistant Prompt -> User Prompt... -> Assistant Prompt
在此结构中,Assisant Prompt的主要作用是向大模型展示历史对话记录,并明确标注哪些内容源于用户的输入。通过这种结构模式数据预训练和微调的大模型能够理解:这些并非即时用户输入,而是对话历史。这有利于大模型更好把握上下文信息,从而更准确回应后续问题。
- 将核心角色定义和规则置于System Prompt中
- 用户交互内容放在User Prompt里
[
{
role: 'system',
content: this.cachePrompt,
},
{
role: 'user',
content: query,
},
];
# 10-AI Search和普通Search有什么区别
- 本质区别在于是否具备语义理解、动态决策和主动推动能力
| 维度 | 传统搜索 | AI Search |
|---|---|---|
| 技术基础 | 关键词匹配 + 倒排索引 | LLM + 知识图谱 + 强化学习 |
| 交互方式 | 用户输入明确关键词->返回匹配结果 | 自然语言提问 -> 理解意图 -> 动态推理答案 |
| 输出形式 | 链接列表(需用户二次筛选) | 结构化答案 + 多模态结果 + 溯源依据 |
| 目的 | 快速检索已有的信息 | 解决问题(甚至执行动作) |
- 核心能力差异
- 语义理解vs 字符匹配
- 传统:匹配关键词出现频率
- AI-Search:理解上下文和隐含需求
- 静态检索vs动态推理
- 传统搜索:仅聚合现有内容
- AI-Search:智能体模式
- 语义理解vs 字符匹配
# 11-什么是DeepSearch
DeepSeach的核心理念是通过在搜索、阅读、推理三个环节不断循环往复、直到找到最优答案。搜索环节利用搜索引擎探索互联网,而阅读环境则专注于对特定网页进行详尽的分析。推理环节则负责评估当前的状态,并决定是应该将原始问题拆解为更小的子问题
# 12-AI Agent和AI Workflow的区别在哪里
AI Workflow的运行过程都是预定义设计好的,AI Agent是运行时进行自主决策。我们在判断一个系统到底是哪一类时,主要是看它能不能在运行过程中动态决策,而不是看system prompt等提示词有多长。
| 维度 | AI Agent | AI Workflow |
|---|---|---|
| 本质 | 具有自主决策能力的智能实体 | 预设步骤的任务自动化流程 |
| 类比 | 有思考能力的员工 | 工厂的流水线 |
| 决策时间 | 设计阶段 | 运行阶段 |
| 决策权 | 自主决策 | 按预设规则执行 |
| 可复现性 | 稳定可复现 | 需要实时记录行动log |
| 运行成本 | 可精准估算 | 存在波动性 |
AI Agent是”思考者“,解决做什么(what)的问题,AI Workflow 则是执行者,解决怎么做How的问题
# 13 -在AI Agent中,function call如何把外部工具变成大模型可以理解的方式
将外部工具转化为大模型可理解方式的核心机制: 接口描述标准化与执行逻辑衔接
实现LLM/AIGC大模型理解并调用外部工具、插件或APi的核心,在于建立一套标准化的接口描述机制,并构建一个可靠的执行桥梁。该过程包含两个关键环节:
- 接口描述标准化
- 定义结构化描述:为每个工具设计一个符合特定调用格式(常用如JSON/XML Schema)的结构化接口定义。该Schema必须清晰包含以下要素:
- 唯一标识符
- 功能说明书
- 参数规格
- 执行逻辑衔接
- 向大模型提供工具目录: 在每次模型交互时,将当前所有可用工具的标准化描述作为上下文信息,整合到提示词信息的特定部分传递给大模型
- 解析模型调用指令:应用程序持续监听模型的输出响应。一旦检测到符合预定义格式(如特定JSON/XML结构)的函数调用指定,立即进行解析
- 定位并执行目标工具:根据解析出的工具标识符,定位到对应的外部工具/插件/API实现
- 参数映射与校验: 从调用指令的参数列表中提取参数值,执行必要的类型转换和有效性校验,最终调用实际工具的接口
- 获取与处理执行结果:捕获工具执行后的结果
- 结果反馈闭环:将工具执行的结果格式化为文本信息,再次输入给大模型。
本质概括:该机制的核心是为每个外部工具创建一份清晰易懂的”自然说明书“,使模型能够理解其功能。同事,建立一个“翻译与执行层“,负责将大模型依据说明书生成的操作指令(JSON/XML Call) 翻译并转化为对实际工具的具体调用动作,并将工具的操作结果报告翻译回大模型能够处理的信息
# 14-在AI Agent中,大模型如何学习到Function Calling能力?
Function Calling 能力不是LLM/AIGC大模型原生具备的,当前AI主流的方式是通过监督微调(SUpervised Fine-tuning, SFT)来实现LLM/AIGC大模型对Function Calling能力的学习。
Function Calling 能力微调训练的核心思想:
- 获取识别意图:理解用户的请求是否需要借助外部工具/函数来完成,而不是直接生成文本回答。
- 获取参数提取与格式化能力:如果需要调用函数,正确的从用户请求中抽取出所需的参数,并按照预先定义的格式(JSON/XML)生成函数调用的指令。
Function Calling的微调过程:
- 数据集制作:一个用户请求,可以是包含调用函数的内容,也可以是不包含调用函数的内容。比如:给我写一首大气的诗.
- 可用函数/工具描述:一个结构化的描述,告知大模型当前有哪些函数可用,每个函数的用途,所需参数以及类型和描述。这个描述本身通常就是文本,需要设计一个清晰的格式(JSON,XML)
- 期望的输出:如果需要调用函数:一个特定格式的字符串,通常是包含函数名和提取出的参数的JSON、XML对象;如果不需要调用函数、大模型直接生成文本回答。
- 数据集整体质量要求:
- 数据多样性:需要足够多、覆盖各种场景的高质量数据
- 函数描述的清晰度:函数描述的质量直接影响模型能否正确理解和使用函数
- 负样本:需要包含足够多明确不需要调用Function的样本,防止模型”过渡触发“Function调用
Function 参数结构化格式例子:
{
"name": "get_stock_change",
"arguments": {
"stock_name": "腾讯股票",
}
}
数据集格式
{
"conversations": [
{
"from": "human",
"value": "帮我查询一下今天股票的涨跌幅情况?"
},
{
"from": "gpt",
"value": "当然,我可以帮忙,请问你对哪只股票感情兴趣?"
},
{
"from": "human",
"value": "腾讯股票"
},
{
"from": "gpt",
"value": "{\n\"function\": \"get_stock_change\",\n\"arguments\": {\n\"stock_name\": \"腾讯股票\"\n}\n}"
}
]
}
- 选择基础模型:选择一个具备强大指令遵循能力的预训练LLM/AIGC大模型
- 格式化训练:将每条数据样本组合成大模型可以理解的格式。通常是将数据集中的"用户输入"和”可用函数/工具描述“拼接起来作为模型输入,将期望的输出作为目标输出。需要使用特定的分割符或模板来区分不同部分。
- 进行微调训练:使用标准的SFT方法(全参数微调或者训练LoRA)在特定数据集上进行微调训练。大模型的优化目标是最小化预测输出和期望输出之间的差异。大模型通过学习这些样本,学会根据用户输入和可用函数描述,决定是直接回答还是生成特定格式的函数调用JSON、XML
# 15- 当前 AI Agent 有哪些局限性
- AI Agent的幻觉问题:AI Agent中的核心LLM/AIGC大模型可能会生成不准确的信息
- 上下文长度与规划缺陷:LLM/AIGC大模型的上下文窗口有限,导致AI Agent难以处理长期有效任务和自我反思
- 多模态处理能力不成熟:不管是B端还是C端场景,很多需求都是处理图像、文本、视频、音频等异构数据,但是多数AI Agent仍以文本这个单一模态为主
- 行业适配困难:企业级场景要求零失误,但通常AI Agent容错率高,难以满足医疗、金融等高风险领域需求。垂直行业业务逻辑复杂,需深度绑定数据与流程。
- 计算成本高: AI Agent运行推理会消耗大量计算资源。
# 16- 当前 AI Agent有哪些主流的评价指标
- 任务成功率:层级任务完成率、郭晨轨迹精确度、长周期策略稳定性等
- 工具调用准确率
- 推理质量
- 用户满意度
# 17-. AI Agent如何具备长期记忆能力?
要让AI Agent具备长期记忆能力,需要解决LLM/AIGC大模型固有的上下文窗口限制和无状态缺陷
具备长期记忆的AI Agent需要采用 分层存储 + 智能检索 架构,核心是通过向量化、摘要压缩、混合数据库 打破上下文窗口限制
- 长期记忆的架构设计
- AI Agent的记忆需模拟人脑结构,分为三层协同工作:
- 短期记忆:通过上下文窗口(如transfor的token限制)维持当前对话连贯性,但容量有限制(通常4k-128k token)
- 中期记忆:将对话关键信息压缩为摘要或嵌入向量,存储于向量数据库,支持语义检索
- 长期记忆:持久化存储用户画像、行为习惯等结构化数据,使用SQL/NoSQL数据库或者知识图谱实现跨会话记忆
- 关键实现技术
- 记忆生成与压缩
- 摘要提炼
- 每次对话结束后,用专用LLM生成摘要
- 嵌入向量化
- 通过BERT或OpenAI Embedding将文本转为向量,便于高效检索
- 记忆检索与更新
- 多模态检索:结合语义搜索(向量相似度) + 时间过滤(最近事件优先) + 规则筛选(如重要度评分)
- 冲突消解:当新旧记忆矛盾时,由LLM裁决或设置衰减权重
- 记忆集成至Agent 将检索结果动态注入Prompt
m.add(user_query, user_id='Alice)
related_memories = m.search('推荐电影', user_id='Alice') #检索相关记忆
prompt = f"User's historical preferences: {related_memories}. Current query: {new_query}"
response = llm.generate()
# 18- AI Agent中的以及机制的原理与作用
- 为什么需要记忆? - 从金鱼脑说起
你:我叫小明,我喜欢打篮球。
AI:你好小明!打篮球是一项很棒的运动。
你:我最好的朋友叫小王。
AI:小王听起来是个不错的朋友。
你:那我和小王周末经常一起做什么?
这时,AI不会记忆之前的对话,就像是一条只有7秒记忆的金鱼。
核心问题:标准的LLM是”无状态“的,每次对话,它都只基于你当前输入的提示词来生成回答,一旦对话结束,这些上下文信息就蒸发了
而一个真正的AI Agent,是需要执行复杂的,多步骤任务的(比如帮你规划整个旅行行程,作为客服处理一个完整的客诉,作为游戏角色与你长期互动)。如果它没有记忆,每一步都像是从头开始。
所以。记忆机制就是为了让AI Agent拥有持续学习、积累经验,并基于完整上下文进行决策的能力。
- 记忆机制的原理:它如何工作?
- 记忆的类型(像大脑的不同功能区)
- 短期记忆:
- 是什么:相当于Agent的工作台或者大脑当前活跃区域。它保存着当前任务直接相关的、最近的信息
- 技术实现:通常就是对话上下文。当你与Agent聊天时,你之前说的N句话(比如最近10轮对话)会作为提示词的一部分,一起送到模型,让它知道刚才我们聊了什么
- 长期记忆
- 是什么:相当于Agent的个人日记或知识库。它存储着需要被长期保留的重要信息,比如你的个人偏好,从过往任务重学到的经验,关于世界的事实
- 技术实现:一个外部向量数据库。这是记忆系统的核心。
- 步骤1:编码:当AI认为某段信息很重要,他会通过一个模型将这段时间转换为一串数字
- 步骤2:存储:将这串数字和对应的原始文本一起存入数据库
- 步骤3:检索:当需要用到记忆时,AI会将当前问题也转换为向量,然后在数据库里搜索语义上最相关的向量片段
- 记忆的流动:一个完整的闭环一个配置了记忆机制的AI Agent,其工作流程是这样的:感知 -> 思考 -> 行动 -> 记忆 的循环
- 感知: Agent接收到新的信息
- 检索:Agent自动从长期记忆库中搜索相关的记忆
- 思考:Agent将新的输入 + 检索到的长期记忆 + 当前的短期记忆组合成一个丰富的提示词,送给大语言模型进行推理
- 行动:大语言模型基于完整的上下文,生成回答
- 记忆:Agent决定是否将这次交互中有价值的信息存储到长期记忆中,以备将来使用。同时,这次对话本身进入了短期记忆的上下文窗口
3.记忆机制的作用:它带来了什么
- 记忆机制从根本上提升了AI Agent的能力天花板,使其从”工具“向”伙伴“演进
- 实现连续性与个性化
- 作用:让 Agent能够记住用户的身份、偏好、习惯和历史互动。你不需要在每次对话中重复介绍自己
- 积累与学习能力
- 作用: Agent可以从过去的成功与失败中学习。它可以把解决过的问题和方法存入记忆,下次遇到类似情况时,直接调用,提高效率
- 维持状态与上下文
- 作用:在复杂的多步骤中,记忆机制帮助Agent维持任务的状态,知道我已经完成了哪几部,下一步该做什么
- 支持复杂推理与规划
- 作用:只有拥有丰富的背景知识,才能进行深度的、基于上下文的推理和长远规划
- 一个生动的比喻:图书管理员
可以把AIAgent的记忆机制想象成一个超级图书馆管理员
- 大语言模型:是这位管理员本身的知识和口才
- 短期记忆:是他手边正在翻阅的那几本书
- 长期记忆:是整个庞大的图书馆藏书
- 检索记忆:是管理员掌握的高效图书检索系统。当他需要回答时,他会先用自己的口才(LLM),结合手边的书(短期记忆),同时用检索系统 从图书馆(长期记忆)找到最相关的书籍来佐证,最后给出一个完美的答案。
总结: 记忆机制是AI Agent的灵魂档案室,它将大语言模型一次性,孤立的智能,转变成了持续的,进化的,具备上下文意识的智能。
# 19- 介绍一下AI Agent的上下文工程的原理
- 什么是上下文工程? 简单来说,上下文工程是指为AI Agent精心设计、组织和管理其所能接触到的信息,使其能够更准确、更连贯、更高效地完成任务的一整套方法,策略和技术。
可以想象成一个非常聪明但患有”短期失忆症“的助手准备一个完美的”工作备忘录“。这个备忘录里面包含:
- 它要做什么(任务指令)
- 它之前做了什么(历史对话和行动)
- 它知道什么(相关知识库)
- 它能用什么(可调用的工具列表)
- 它应该注意什么(行为准则和约束)
- 为什么上下文如此重要? - 原理的核心
大模型语言工作机制:它是一种基于上下文额自回归预测模型
- 无状态性:LLM本身是"无状态"的。每次调用之间互不相干。它根据这个文本预测下一个最可能得词/令牌,如此循环。它没有内置的记忆来记住上一次你和它说了什么。
- 上下文窗口是唯一的”工作记忆区“:模型能够看到和处理的全部信息,就是当前这次请求所携带的上下文。这个上下文就是它的整个世界、全部的工作记忆。模型的所有推理、决策和回答,都完全基于所提供的这个上下文。
因此,上下文工程的根本原理就是:通过精心控制模型的”输入信息“,来引导和约束模型的”输出行为“,从而模拟出智能、连贯、有状态的代理行为。
- 上下文的关键组成部分
一个为AI Agent设计的高质量上下文,通常包含以下几个核心部分,这也是上下文工程需要精心构筑的模块
- 系统提示|角色设定
- 内容:定义Agent的人设,核心职责、目标和行为规范
- 作用:在任务开始时为Agent设定一个稳定的”心智模型“,告诉它”你是谁“、你该做什么以及你该如何表现
- 任务指令与目标
- 内容:清晰、具体地描述当前需要完成的任务
- 作用:为本次交互提供明确的方向
- 对话与行动历史
- 内容:记录用户与Agent之间多轮对话的完整记录,以及Agent之前调用工具/执行行动的内容和结果
- 作用:提供连贯性。让Agent能够引用之前说话的话,理解用户的指代,并避免重新操作
- 原理:这是模拟“记忆”和状态的关键。没有历史,每个问题对Agent来说都是全新的
- 外部知识与文档
- 内容:通过检索增强生成等技术,从向量数据库、知识库或网络中获取、与当前任务相关的信息
- 作用:弥补LLM知识的时效性和专有性不足,为其决策提供事实依据。
- 工具与函数定义
- 内容:描述Agent可以调用的外部工具的列表,包括他们的名称、描述、参数格式等
- 作用:扩展Agent的行动能力,使其不在局限于文本生成,而是可以执行具体操作
- 原理:通过提供工具描述,引导模型在遇到特定情况时选择并结构化调用正确的工具
- 结构化输出要求
- 内容:要求模型以特定的格式输出其思考过程或最终答案
- 作用:便于后端的程序解析模型的输出,实现自动化流程。这对于Agent的“思考-行动”循环至关重要
- 上下文工程的核心原理和策略
原理1: 分层与优先级 上下文窗口是有限的宝贵资源。必须高效利用
- 策略
- 系统提示优先且稳定:系统提示通常放在最前面,并且在整个会话中尽量保持稳定,它是Agent的基石
- 相关性筛选:不是所有的历史记录和外部知识都同样重要。使用检索器根据当前问题,动态地从海量信息中找出最相关的片段放入上下文。这是RAG的核心
- 历史摘要/压缩:当对话很长时,将遥远的对话历史压缩陈一个简洁的摘要,而不是完整地保留所有的原始文本,以节省空间。
原理2:思维过程与推理框架 要让Agent完成复杂任务,需要引导它进行逐步推理
- 策略:
- 在上下文中提供思考模板:通过在系统提示中明确要求Agent按照思考-行动-观察的步骤来工作
- 思考:分析现状,决定下一步做什么
- 行动:调用工具或生成回答
- 观察:记录行动的结果
- 示例(ReAct模式)
思考:用户需要知道北京的天气来决定是否带伞。我知道当前日期,但不知道实时天气。我需要调用天气查询工具。
- 在上下文中提供思考模板:通过在系统提示中明确要求Agent按照思考-行动-观察的步骤来工作
行动:调用工具[get_weather(城市="北京")] 观察:工具返回结果:北京,晴,气温25°C。 思考:根据天气信息,北京是晴天,不需要带伞。我可以把这个信息告诉用户。 回答:北京今天是晴天,气温25°C,出门不需要带伞哦! ``` - 通过将这种结构化的思考过程也放入上下文中(通过是模型的输出中),我们迫使模型进行更深入,更逻辑化的推理,而不仅仅是给出最终答案
原理3:动态管理与状态维持 由于上下文窗口的限制与任务的长期性,上下文必须是动态变化的
- 策略:
- 滑动窗口:只保留最近N轮对话,丢弃最老的对话。简单但可能丢失关键长期信息
- 智能摘要: 如上所述,由Agent或一个单独的流程定期对过去的交互进行总结,将摘要而非全文放入上下文。
- 向量化长期记忆:将重要的用户信息、任务状态等存储在外部数据库。等需要时,再通过检索的方式将其拉回上下文。这实现了长期记忆与工作记忆的分离
# 20 -主流的AI Agent
| 框架名称 | 执核心特点特征 | 典型应用场景 |
|---|---|---|
| LangChain | 模块化组件、生态丰富,链式编排工作流 | 快速原型验证,高度定制的单Agent应用,如文档问答,客服自动化 |
| LangGraph | 基于图的工作流,强大的状态管理和循环控制 | 复杂决策系统,多Agent协调,长周期任务 |
| CrewAI | 角色驱动,强调智能体检的结构化分工与写作 | 内容创建,数据分析,商业策划等有明确分工的协作任务 |
| AutoGen | 对话驱动,通过多轮自然语言对话实现智能体协作 | 研究探索,代码生成,需要创建新思维的场景 |
| Semantic Kernel | 企业级集成,强大的安全合规性,插件架构 | 现有系统的智能化改造 |
| Dify | 低代码/零代码,可视化界面,快速构建和部署 | 中小企业快速构建知识库问答,快速原型 |
| OpenAI Agents SDK | 轻量级,支持多模型,内置调式工具 | 邮件优雅的多代理系统 |
# 21- 主流的AI Agent中包含哪些核心模块
五大核心模块
- 规划模块:这是AI Agent的大脑,负责思考与决策
- 任务分解:将负责的用户指令拆解成一系列可执行的子任务
- 战略制定:规划完整任务的最佳路线和顺序,处理子任务之间的依赖关系
- 反思与校准:在行动过程中或结束后,评估当前结果是否满足要求,并进行自我纠正。这是实现复杂任务的关键
- 工具使用模块
- 工具库:一个Agent可以调用的外部工具,API或函数的集合
- 调用和执行:Agent 根据规划模块的决策,选择正确的工具,生成正确的参数,并执行调用
- 结果处理:接收工具返回的结果,并将其标准化,传递给其他模块
- 记忆模块 这是Agent的经验库,用户存储和检索信息,分为
- 短期记忆:保留当前对话或任务链的上下文,确保对话的关联性
- 长期记忆:通过向量数据库等技术,保存跨对话的长期知识、用户偏好、历史决策和结果,供未来任务参考。
- 行动输出模块 这是Agent的最终表达。将内部决策转化为用户可感知的输出
- 生成最终答案:在不需要调用工具或所有步骤完成后,生成自然语言回复
- 生成结构化指令:当需要与环境交互时,生成工具调用的指令
- 交付最终话结果:例如:返回一篇写完的文章,一段生成的代码,一个创建好的文件等
串联模块的灵魂:感知与推理循环 单独拥有这些模块还不够,最关键的是让它们运转起来的核心控制流,即感知-思考行动循环,这通常由大模型的推理能力驱动
感知:接收用户输入和环境的反馈
思考
- 规划模块结合记忆模块(历史上下文和知识):决定下一步该做什么
- 如果需要外部工具,工具使用模块被激活
- 行动
- 工具使用模块执行调用,并将结果协会记忆模块
- 规划模块:根据结果进行反思,判断任务是否完成。如果未完成,回到第二步继续思考,如果完成,则通过行动输出模块给出最终结果
一个AI Agent的智能程度不仅取决于其核心大模型的能力,更取决于这些大模型设计的精巧程度与协作效率
# 22- AI Agent中Memory和RAG有哪些区别
AI Agent中Memory和RAG的本质区别
| 维度 | Memory | RAG |
|---|---|---|
| 核心目的 | 维持AI Agent的连续性、个性化和状态感知 | 提供外部知识检索以增强生成能力 |
| 存储内容 | 会话历史、用户偏好、行动轨迹、内部状态 | 结构化/非结构化文档、知识库、事实数据 |
| 时间维度 | 短期+长期记忆,具备时间序列特性 | 静态知识,通常不随时间频繁变化 |
| 更新频率 | 实时、高频 | 低频、批量更新 |
| 数据结构 | 图结构、序列结构、键值对、向量 | 文档、向量、索引结构 |
技术架构对比
- Memory机制
class AgentMemory:
def _init_(self):
// 短期记忆(对话上下文)
self.short_term = []
// 长期记忆(向量存储)
self.long_term = VectorStore()
// 经验记忆(强化学习)
self.experience = ExperienceReplay()
// 工作记忆(当前任务状态)
self.working = TaskState()
# 关键组件
# - 对话历史管理
# - 状态跟踪器
# - 经验回放缓冲池
# - 记忆压缩/遗忘机制
# - 记忆检索和关联
- RAG系统
# 典型RAG架构
class RAGSystem:
def _init_(self):
// 文档处理流水器
self.doc_processor = DocumentProcessor()
# 向量化模型
self.embedder = EmbeddingModel()
#向量数据库
self.vector_db = VectorDatabase()
#检索器
self.retriever = Retriever()
# 重排器
self.reranker = Reranker()
# 关键组件
# - 文档分割和清晰
# - 向量索引构建
# - 相似性搜索算法
# - 上下文压缩和重组
# - 多跳检索能力
功能差异详细分析
- Memory的核心功能
- 会话连续性
memory = [ {"role": "user", "content": "我喜欢科幻电影"}, {"role": "assistant", "content": "推荐《星际穿越》"}, {"role": "user", "content": "还有类似的吗"}, # 这里依赖记忆 ] - 个性化适配
- 学习用户偏好
- 适应交互风格
- 记住用户特定信息
- 状态保持
# 任务状态记忆 task_state = { "current_step": 3, "completed_steps": ["收集需求", "分析数据", "生成大纲"], "next_action": "编写执行计划", "constraints": ["预算限制: $100", "时间限制:7天"], }- 经验学习
- 从成功/失败中学习
- 优化决策策略
- 形成肌肉记忆
- 会话连续性
RAG的核心功能
- 知识检索
#从知识库检索相关信息
query = "如何修复PostgreSQL连接错误?"
retrieved_docs = vector_db.similarity_search(
query=query,
k=5, # 返回5个最相关文档
filter={"source": "官方文档"}
)
- 事实增强
- 提供最新信息(避免LLM知识过时)
- 提供详细数据(统计数字、技术细节等)
- 提供权威来源引用
- 领域专业化
# 专业领域知识搜索 medical_rag = RAGSystem( docuements_medical_textbooks, embedding_model="med-bert", retrieval_strategy="hybrid_search" ) - 幻觉抑制
- 基于真实文档生成回答
- 提供可验证的参考风险
- 减少编造信息的风险
存储和检索方式对比
Memory存储方式
# 1. 向量记忆 memory_vectors = embedder.encode([ '用户偏好素食', '用户是软件工程师', '用户上次询问python问题', ]) # 2. 图记忆 memory_graph = { "user": {"likes": ["scifi", "coding"], dislikes: ["horror"]}, "projects": {"current": "AI Agent", completed: ["Web App"]}, "conversations": {"today": 5, "total": 342}, } # 3. 序列记忆 memory_timeline = [ {"timestamp": "10:00", "action": "started_task", "details": "..."}, {"timestamp": "10:15", "action": "requested_data", "details": "..."}, {"timestamp": "10:30", "action": "completed_step", "details": "..."} ]RAG存储方式
# 文档分块和向量化
documents = [
"PostgreSQL安装指南...",
"数据库优化技巧...",
"常见错误解决方案..."
]
# 创建向量索引
vector_index = VectorIndex(
documents=documents,
chunk_size=500, #500字符一个块
overlap=50, #块间重叠50字符
embedding_model="text-embedding-ada-002"
)
# 支持多种检索模式
retrieval_methods = {
"dense": vector_index.dense_retrieval,
"sparse": vector_index.bm25_retrieval,
"hybrid": vector_index.hybrid_retrieval,
"multi_vector": vector_index.multi_vector_retrieval
}
更新机制对比
- Memory更新特性
class MemoryUpdate:
# 1. 增量更新
def add_experience(self, experience):
self.experience_buffer.append(experience)
if len(self.experience_buffer) > capacity:
self.compress_memory() #记忆压缩
# 2. 重要性加权
def weight_by_importance(self, memory_item):
# 基于使用频率、情感强度、任务相关性加权
importance_score = (
frequency * 0.3 +
recency * 0.2 +
emotional_intensity * 0.2 +
task_relevance * 0.3
)
return importance_score
# 3. 选择性遗忘
def forget_less_important(self, threshold=0.5):
for item in self.memories:
if item.importance < threshold:
self.archive(item) # 归档而非删除
- RAG更新特性
class RAGUpdate:
# 1. 批量更新
def update_knowledge_base(self, new_documents):
# 重新处理整个文档集或增量更新
if self.incremental_update_supported:
self.vector_db.add_documents(new_document)
else:
# 重新重建整个索引
self.rebuild_index(existing_docs + new_document)
# 2. 版本控制
def create_snapshot(self, version):
self.snapshots[version] = {
"document": deepcopy(self.docuemnts),
"index": deepcopy(self.vector_index),
"timestamp": datetime.now(),
}
# 3. 质量过滤
def filter_by_quality(self, document, min_quality_score= 0.7);
return [doc for doc in documents
if self.quality_score(doc) >= min_quality_score]
检索策略差异
- Memory检索策略
# 基于上下文的关联检索
def retrieve_relevant_memories(self, current_context, top_k=3):
# 1. 时间相关性
recent_memories = self.get_recent_memories(hour=24)
# 2. 语义相关性
content_embeddding= self.embedder.encode(current_content)
similar_memories = self.vector_memory.search(
query_vector=context_embedding,
k=top_k
)
# 3. 任务相关性
task_related=self.get_task_memories(
task_type=current_context.task_type
)
# 4. 综合评分
scored_memories = self.rank_memories(
recent_memories + similar_memories + task_related,
weights={"recent": 0.4, "semantic": 0.4, "task": 0.2}
)
- RAG检索策略
# 基于查询的知识检索
def retrieve_relevant_documents(self, query, top_k=5):
# 1. 密集向量查询
dense_results=self.vector_db.similarity_search(
query=query,
k=top_k*2
)
# 2. 稀疏检索(关键词)
sparse_results=self.bm25_retriever.search(
query=query,
k=top_k*2
)
# 3. 混合检索
hybrid_results = self.hybrid_search(
dense_results, sparse_results,
dense_weight=0.7, sparse_weight=0.3
)
# 4. 重排序
reranked_results = self.reranker.rerank(
query=query,
document=hybrid_results
)
return reranked_results[:top_k]
实际应用场景对比
- 适合使用Memory的场景
- 对话系统
# 需要记住对话历史
chatbot_with_memory = ChatAgent(
memory=ConversationMemory(max_turns=10),
personality=PersonalityTrait(
tone='friendly',
expertise_level='intermediate'
)
)
- 持续学习Agent
# 从经验中学习的Agent
learning_agent= RLAgent(
memory=ExperienceReplayBuffer(size=10000),
police_network=PoliceNet(),
update_frequency=100 # 每100步更新一次
)
- 个性化助手
# 记住用户偏好的助手
personal_assistant = Assistant(
memory=UserProfileMemory(
preferences=["素食","早起", "技术新闻"],
habits=["每天锻炼", "周末阅读"],
constraints=["对坚果过敏", "预算有限"]
)
)
- 适合使用RAG的场景
- 企业知识库问答
# 基于企业文档的问答
company_qa=RAGSystem(
documents= [
"员工手册.pdf",
"技术文档",
"项目报告",
"会议记录",
],
retrieval_config={
"chunk_size": 1000,
"search_strategy": "hybrid",
"reranker": "cross-encoder",
}
)
- 事实核查系统
# 验证信息的准确性
face_checker=FaceCheckingSystem(
knowledge_sources=[
WikipediaDump(),
NewsArticles(),
AcademicPapers(),
GovernmentReports()
],
citation_required=True,
confidence_threshold=0.8
)
- 技术文档助手
# 提供技术支持和文档查询
tech_support=TechDOcAssistent(
docs=["API文档", "教程", "FAQ", "错误代码手册"],
search_features={
"code_search": True,
"error_code_lookup": True,
"version_specific": True,
}
)
# 23 - AI Agent中Agents、Teams、Worflows三者有哪些区别
- Agents(代理)
- 定义:AI程序,由LLM控制执行流程
- 核心组件:
- Model: 控制执行流程,决定是推理、使用工具还是响应
- Instructions: 指导模型如何使用工具和响应
- Tools: 使模型能够执行操作并与外部系统交互
- 扩展能力
- Memory: 存储和回忆之前交互的信息
- Storage: 在数据库中保存会话历史和状态
- Knowledge: 运行时搜索的知识库
- Reasoning: 在响应前思考和分析结果
- 适应场景:单一任务执行,如问答、搜索、内容生成等
- Teams(团队)
- 定义:多个子AI Agent的集合,协同工作完成复杂任务
- 核心特性:
- 每个成员可以有不同的专场、工具和指令
- 由Team Leader协调任务分配
- 支持多种协作模式
- 适用场景
- 需要推理和协作的任务
- 研究和规划
- 多工具决策
- 开放性问题解决
- Worflows
- 定义:通过定义的步骤编排Agents、Teams和函数,提供结构化自动化
- 核心构建块
组件 用途 Step 基本执行单元 Parallel 并行执行多个步骤 Condition 条件执行 Loop 迭代执行直到满足条件 Router 动态路由选择执行路径 - 执行模式
- 顺序执行:步骤按顺序依次执行
- 并行执行:独立任务同时运行
- 条件执行:基于条件分支
- 循环迭代:迭代直到满足质量条件
- 动态路由:根据内容选择最佳路径
- 适用场景
- 需要确定性、可预测的多步骤执行
- 数据处理管道
- 内容创建流程
- 需要可重复、可靠的自动化流程
# 34 - AI Agent中的AgentOS的核心概念
- 什么是AgentOS AgentOS是AI Agent的操作系统,为Agent提供运行环境、资源管理和服务抽象层
| 传统OS | AgentOS | 作用 |
|---|---|---|
| 进程管理 | Agent管理 | 创建、调度、监控Agent |
| 文件系统 | 知识/记忆存储 | 数据持久化和管理 |
| 设备驱动 | 工具/API抽象 | 统一接口调用外部资源 |
| 网格线 | 通信协议 | Agent间通信和协作 |
| 安全机制 | 权限控制 | 访问控制和数据隔离 |
- AgentOS的核心架构
┌─────────────────────────────────────────┐
│ 应用层 (Application Layer) │
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
│ │ Agent A │ │ Team B │ │ Agent C │ │
│ └─────────┘ └─────────┘ └─────────┘ │
├─────────────────────────────────────────┤
│ AgentOS核心层 (Core Layer) │
│ ┌─────────┬─────────┬──────────┐ │
│ │ 运行环境 │ 资源管理 │ 服务发现 │ │
│ └─────────┴─────────┴──────────┘ │
├─────────────────────────────────────────┤
│ 基础设施层 (Infrastructure) │
│ ┌─────┬──────┬──────┬──────┬─────┐ │
│ │ 数据库 │ 向量库 │ 缓存 │ API服务│ │
│ └─────┴──────┴──────┴──────┴─────┘ │
└─────────────────────────────────────────┘
- AgentOS的核心功能
| 功能 | 说明 |
|---|---|
| 运行Agents/Teams/Workflows | 创建新的运行实例,支持新会话或现有会话 |
| 会话管理 | 检索、更新、删除会话 |
| 记忆管理 | 存储和检索持久化记忆 |
| 知识库管理 | 上传、管理和查询知识库 |
| 评估管理 | 运行评估和跟踪性能指标 |
| 指标监控 | 获取分析数据和使用统计 |
AgentOS作为AI Agent的基础设施,其核心价值在于降低Agent开发复杂度、提高系统可靠性、促进Agent生态发展。
# 35- 什么是AIAgent系统中的子 Agent动态加载
动态加载是指在运行时根据需要加载和初始化组件的能力,而不是在编译或启动时固定加载所有组件。在AI Agent系统中,这意味着:
- 按需加载:只在需要加载时加载特定Agent
- 热插拔:运行时添加/移除Agent而不是重启系统
- 隔离性:每个Agent独立运行环境
- 版本管理:支持不同版本的Agent共存
动态加载是构建大型、复杂AI Agent系统的关键技术,它提供了灵活性、可扩展性和资源效率。通过合理的架构设计和优化,可以构建出既能快速响应需求变化,又能保持系统稳定和高性能的AI Agent系统。
# 36- 用户存储AI Agent长期记忆的主流数据库有哪些?
目前AI Agent系统中需要使用数据库来存储AI Agent的会话、记忆、知识等数据
关系型数据库
| 数据库 | 说明 |
|---|---|
| PostgreSQL | 生产环境推荐,支持JSONB,异步操作 |
| MYSQL | 企业级关系型数据库 |
| SQLite | 轻量级嵌入式数据库,适合开发测试 |
| Neon | 无服务器PostgreSQL平台 |
| Supabase | 开源Firebase替代方案 |
| SingStore | 实时分析数据库 |
NoSQL数据库
| 数据库 | 说明 |
|---|---|
| MongoDB | 流行的文档数据库 |
| DynamoDB | AWS NoSQL服务器 |
| Firestore | Google 文档数据库 |
| redis | 内存数据存储 |
| SurrealDB | 多模态数据库 |
存储的数据类型:配置数据库后,AI Agent系统可以自动存储
- Seesions - 会话历史和状态
- User Memories-用户长期记忆
- Knowledge-知识库内容
- Metrics- 使用指标
# 37- AI Agent中记忆机制包含哪些核心组件
当前主流的AI Agent系统中,记忆机制的主要组件包括:
- 记忆存储:存储用户的个性化信息
- 记忆检索:支持多种检索方式
- 记忆优化:通过总结等方式压缩记忆
- 记忆管理:增删改查记忆
- 用户隔离:通过user_id 隔离不同用户的记忆
- 异步支持:同时支持同步和异步操作
- AI驱动:使用LLM分析对话内容,智能提取记忆
- 主题分类:支持为记忆添加topics,便于分类检索
# 38- AI Agent中记忆机制运行的核心流程是什么样的
- 用户输入问题,AI Agent进行内容回答
- 触发AI Agent的记忆机制判断逻辑,获取记忆机制的系统提示词,配套tool工具,以及历史工具信息
- 调用LLM大模型做诶判别模型,进行决策;或者使用规则进行决策。来确定是否将当前的回答信息进行处理与记忆信息的更新
- 如果确定进行记忆信息的更新,则包括更新记忆信息、删除记忆信息、更新记忆信息以及保持不变等操作
# 39- 介绍一下AI Agent中Pre-hook(前置钩子)的作用
- 核心概念:什么是钩子 在软件工程中,钩子是一种事件驱动的编程模式。它允许你在程序执行的特定关键点插入自定义的代码,从而不修改核心流程的情况下,改变或增强程序的行为。
Pre-hook和Post-hook就分别作用于“调用工具/模型”这个动作的之前和之后。
- Pre-hook(前置钩子)的详细定义和作用 定义:Pre-hook是在Agent的核心操作之前自动触发执行的一段自定义代码或函数 核心作用:对即将发生的操作进行审查、修改、增强或决策,从而实现对Agent行为的精细化控制和安全管理
四大很作用详解:
- 输入预处理与增强:在请求发送给LLM或工具之前,对输入数据进行加工
- 安全与合规审查
- 流程控制与决策:Pre-hook 可以决定核心操作是否执行,或者如何执行。
- 可观测性与调试:在执行前记录关键信息,便于监控、审计和问题排查。
- Pre-hook和Post-hook的对比 | 特性 | Pre-hook | Post-hook | |-------|-------| -------| | 执行时机 | 在核心(调用LLM)操作之前 | 在调用LLM之后,结果返回用户之前 | | 主要操作对象 | 输入(用户查询、工具参数) | 输出(LLM响应、工具执行结果) | | 核心目的 | 控制、准备、防护 | 处理、解释、通知 | | 典型应用 | 输入预处理、安全审查、权限校验、流程短路 | 输出格式化、结果验证、错误处理、发送通知、结果存储 | | 能否阻止操作 | 可以 |,通过不能阻止,但可以修改最终返回给用户的结果 |
# 40- 当前主流的AI Agent中Memory机制有哪些细分记忆概念
当前AI Agent系统中的Memory机制可以分为以下四种子记忆概念,共同构成了一个多层次、智能化的记忆系统,旨在让AI智能体(Agent)更懂用户、更会做事、更高效协作。
| 记忆类型 | 核心功能 | 类比 |
|---|---|---|
| 个人记忆 | 理解并适用特定用户 | 像一位贴身的私人管家,记得你的口味和作息 |
| 任务记忆 | 从经验中学习并优化 | 像一个不断更新的项目知识库或SOP |
| 工具记忆 | 数据驱动的工具优化:基于历史使用数据,智能选择并配置最佳工具 | 像一个精通所有工具的高级技师,知道什么活用什么工具最顺手 |
| 工作记忆 | 管理短期上下文,避免溢出:处理长对话中的大量信息,保证核心思考不中断 | 像电脑的内存,临时存放和处理当前任务所需的信息 |
个人记忆:转为理解并适应特定用户而设计。
- 核心思维:不是一视同仁,而是因人而异。通过记录与单个用户的长期互动,构建其独特的画像。
- 关键特性:
- 个体偏好:记忆用户的习惯,兴趣和交互风格
- 上下文适应:智能地根据时间、场景调用相关记忆。
- 渐进式学习:通过长期互动,逐步加深对用户的理解,形成深度认知。
- 时间感知:在记忆存储和检索时都考虑时间因素,提升用户体验和粘性
任务记忆:专注于任务执行经验中学习,实现自我改进
- 核心思想:将任务执行中的过程性知识沉淀下来,供所有智能体复用,避免重复试错
- 关键特性:
- 成功模式识别:总结哪些策略有效,并理解其背后的原理
- 失败分析学习:分析错误原因,避免重蹈覆辙
- 对比模式:通过比较不同任务轨迹,提炼出更深刻的见解
- 验证模式:通过专门的验证模式,确认所提取记忆的有效性
- 应用价值:大幅提升多步骤复杂任务的自动化水平和成功率
工具记忆:基于历史性能数据,优化工具的选择和使用
- 核心思想:用数据说话,取代静态、死板的工具调用说明
- 关键特性
- 历史性能追踪:记录工具真实使用的成功率、耗时、Token消耗等量化指标
- LLM-as-Judge评估:让大模型定型分析工具成功或失败的原因,补充量化数据
- 参数优化:从成功的调用中学习最优的参数配置
- 动态指标:将静态的工具文档,转化为基于实际学习成果的,不断更新的活手册
- 应用价值:在需要调用多个API、函数或外部工具的场景中,智能选择最高效、最可靠、最经济的工具组合,降低成本、提高效率。
工作记忆
- 为长周期运行的智能体管理短期上下文,解决上下文长度限制的瓶颈
- 关键机制
- 消息卸载:将冗长的工具输出、中间结果压缩成摘要或保存到外部文件
- 消息重载:通过搜索和读取操作,按需找回被卸载的内容
- 内容价值:支持智能体进行超长对话,处理复杂文档或执行多轮复杂任务,而不会因为上下文窗口被沾满而失忆或性能下降
# 41- MCP服务支持的传输协议有哪些?各传输协议的性能如何?
当前AI Agent系统中的MCP服务支持的传输协议有stdio,Streamable HTTP以及SEE三种。
- stdio传输(最快) 性能特点:
- 延迟最低:直接进程间通信,无网络开销
- 吞吐量最高:直接内存/管道传输,无协议封装
- 资源消耗最小:无需网络栈、HTTP解析等
技术原理
# stdio 传输直接使用标准输入输出流
self._context = stdio_client(self.server_params)
read,write= session_params[0:2] # 直接获取读写流
性能优化:
- 零网络延迟:本地进程间直接通信
- 最小协议开销:JSON-RPC 2.0 直接通过管道传输
- 无序列化开销:数据直接以二进制/文本流传输
- 连接复用:进程生命周期内保持连接
适用场景:
- 本地部署的MCP服务器
- 对延迟敏感的应用
- 高频调用的场景
- 单机环境
性能指标(估算):
- 延迟:<1ms
- 吞吐量: > 100MB/s(取决于管道容量)
- CPU开销: 最低
# Streamable HTTP传输(中等速度)
性能特点:
- 网络传输: 需要HTTP协议栈
- 协议开销:HTTP请求/响应头
- 连接管理:需要处理连接建立和复用
技术原理:
# Streamable HTTP 通过HTTP 请求/响应传输
self._context = streamablehttp_client(**streamable_http_params)
# 使用HTTP协议进行JSON-RPC 2.0 消息交换
性能优势:
- 标准化:基于HTTP,兼容性好
- 可扩展:支持负载均衡、反向代理
- 现代协议:支持流式传输,减少延迟
性能劣势:
- 网络延迟: 即时是本地,也有TCP/IP栈开销
- HTTP开销:请求头、响应头增加传输量
- 序列化开销: JSON序列化/反序列化
适用场景:
- Web部署环境
- 跨网络调用
- 需要负载均衡的场景
性能指标(估算)
- 延迟:5-50ms(取决于网络)
- 吞吐量:10-100MB/s(取决于网络带宽)
- CPU开销:中等(HTTP解析)
# SSE传输(较慢,已废弃)
性能特点:
- 长连接:保持HTTP连接打开
- 文本流:Server-Sent Events格式
- 已废弃:推荐使用Streamable HTTP
技术原理
# SSE 使用Server-Sent Events 长连接
self._context = sse_client(**sse_params)
# 通过SSE流传输 JSON-RPC 2.0 消息
性能劣势:
- SSE协议开销:需要维持长连接状态
- 文本格式限制:智能传输文本,需要base64编码二进制数据
- 单向流限制:虽然可以双向,但设计上偏向服务器推送
- 浏览器兼容性:主要涉及用于浏览器环境
性能指标(估算)
- 延迟:10-100ms
- 吞吐量:5-50MB/s
- CPU开销:较高(SSE解析和连接管理)
详细性能对比表
| 传输协议 | 延迟 | 吞吐量 | cpu开销 | 网络开销 | 适用场景 |
|---|---|---|---|---|---|
| stdio | <1ms | > 100MB/s | 最低 | 无 | 本地部署 |
| Streamable HTTP | 10-100MB/s | 中等 | 有 | Web/网络部署 | |
| SSE | 10-100ms | 5-50MB/s | 较高 | 有 | 已废弃 |
速度排名
- stdio: 最快(本地场景)
- Streamable HTTP:中等
- SSE:最慢(已废弃)
选择建议:
- 本地部署:使用stdio(最快)
- 网络部署:使用Streamable HTTP(现代、标准)
- 避免使用:SSE(已废弃)
# 42- Memory机制设计的核心目标是什么?解决了AI Agent内存管理的哪些痛点?
Memory 机制的核心目的是为AI Agent系统提供统一的内存框架,实现跨用户、任务、Agent的记忆提取、复用和共享。 解决的核心痛点:
- 上下文长度记忆限制:通过工作内存的消息卸载/压缩,降低长文本Token消耗
- 记忆复用性差:任务内存提取跨Agent的成功/失败模式,避免重复试错
- 个性化不足:个人内存基于用户偏好/上下文动态适配交互策略
- 工具使用低效:工具内存基于历史性能优化工具选择和参数配置
- 多场景适配难:分层内存架构适配不用任务(长程交互/多Agent协作/工具调用)
# 43- Memory机制如何实现跨Agent的记忆复用?
在AI Agent系统中,构建跨Agent的记忆复用的实现方式有:
- 构建统一的任务内存库,通过向量存储实现记忆检索
- 提供标准化的内存检索/更新API,支持多Agent访问同一内存空间
- 基于LLM大模型总结任务执行轨迹,生成结构化的可复用记忆。
# 44- 如果要将Memory机制构建到商业级AI Agent系统中,需要考虑哪些工程化问题
- 部署适配: 内存库的分布式存储(如向量数据库集群),支持多Agent并发访问;环境变量配置(FLOW_EMBEDDING_API_KEY/FLOW_LLM_BASE_URL)的安全管理
- 性能优化:上下文压缩的性能损耗(如LLM压缩的耗时),需做缓存/异步处理,内存检索的延迟优化(如向量索引调优)
- 兼容性:与现有Agent框架(如LangChain/Agentscope)的集成适配;解耦第三方依赖(如flowllm库),降低版本冲突风险;
- 可观测性:内存使用/压缩比?检索命中率的监控;工具内存的性能数据(成功率/耗时)可视化。
# 45- AI Agent系统中直流的Memory机制的工作流程是怎么样的?
- 信息内容过滤: 过滤出包含重要用户信息的消息
- LLM评分:使用LLM对每条消息进行信息价值评分(0-3分),0分标识无信息,1分表示假设性或虚假内容;2分表示一般信息或时效性信息; 3分表示明确重要信息或用户明确要求记录的内容
- LLM 提取内容总结:使用精心设计的提示词让LLM提取; 用户的基本信息、用户画像信息、兴趣偏好、个性价值观、人际关系、重大生活事件等内容;
- 加载原有记忆,与新记忆进行对比去重
- 更新向量库,将新生成的记忆保存到向量数据库
# 46- AI Agent系统中出现上下文窗口溢出时的主流解决方案有哪些?
在AI Agent系统中,上下文窗口溢出是一个普遍且关键的问题:
典型场景:
- 长时间对话(多轮机制)
- 复杂任务执行(多步骤ReAct)
- 大量工具调用(返回结果累积)
- 浏览器自动化(DOM/AXTree 巨大)
- 代码生成(大量代码上下文)
# 主流解决方案分类
- 历史压缩类方案 方案1.1: 滑动窗口(Sliding Window) 核心思路:只保留最近的N轮对话 优点:
- 实现简单,计算开销小
- 可预测,容易调试
- 适合大多数场景
缺点:
- 缺失中间重要信息
- 固定窗口大小不灵活
- 无法保留关联上下文
适用场景:短期任务、客服对话、简单问答
方案1.2:智能摘要 核心思路:使用LLM将旧对话压缩为摘要 优点:
- 保留关键信息
- 灵活性高
- 压缩比高(10:1甚至更高) 缺点:
- 额外的LLM调用成本
- 可能丢失细节
- 摘要质量依赖模型能力 使用场景:长期对话、咨询服务、知识问答 方案 1.3:语义压缩
优点:
- 智能保留重要信息
- 避免冗余信息
- 压缩效果好
缺点:
- 计算开销大(需要生成embedding)
- 实现复杂
- 可能破坏时序关系
使用场景:知识密集型任务、文档分析
- 内容优化类方案 方案 2.1 选择性保留 核心思路:根据消息重要性选择保留 优点:
- 保留最重要的信息
- 灵活的优先级策略
- 适用不同场景
缺点:
- 需要定义优先级规则
- 可能打乱时序
- 实现复杂
适用场景:复杂Agent系统、多工具调用 方案 2.2 内容裁剪 核心思路:删除消息中的冗余内容 优点:
- 保留完整性对话结构
- 针对性强
- 实现相对简单
缺点:
- 需要识别冗余模式
- 可能影响功能
- 维护成本高 适用场景:浏览器自动化、代码生成、数据处理
- 架构优化类方案 方案3.1: 分层记忆 核心思路:将记忆分为多个层次 优点:
- 平衡了完整性和效率
- 符合人类记忆模型
- 可扩展到超长对话 缺点:
- 实现复杂
- 需要精心设计分层策略
- 维护成本高 适用场景:长期运行的Agent、个人助理、知识管理
方案3.2 外部记忆 核心思路:将历史存储在外部数据库,按需检索 优点:
- 理论上无线容量
- 智能检索相关信息
- 适合知识密集型任务
缺点:
- 需要外部数据库
- 检索可能不准确
- 增加系统复杂度
适用场景: 知识问答、文档分析、客户服务
方案3.3: 多Agent协作 核心思路:将大任务分解给多个专用Agent 优点:
- 每个Agent 上下文独立
- 并行执行,提高效率
- 模块化、易于维护
缺点:
- 系统架构复杂
- Agent间通信开销
- 需要精心设计任务分解
适用场景:复杂任务、工作流自动化
- 模型选择类方案 方案4.1 长上下文模型 核心思路:使用支持更长上下文的模型 优点:
- 简单直接、无需额外实现
- 避免信息丢失
- 保持完整上下文
缺点
- 成本更高
- 响应速度可能更慢
- 不是永久解决方案
使用建议:
- 短期任务:用较小窗口模型 + 压缩
- 中长期任务:用中等窗口模型
- 极长任务:用超长窗口模型
方案 4.2 混合模型策略 核心思路: 不同阶段使用不同模型 优点:
- 平衡性能和成本
- 各阶段最优化
- 灵活性高 缺点:
- 管理复杂度高
- 需求精心设计策略
# 47- 介绍一下AI Agent系统中Skills的原理和作用
Skills概述 Skills是基于Anthropic的Agent Skills规范实现的功能,用于扩展AI Agent的能力,让AI Agent能够逐步发现、获取和使用专业知识和能力
# 核心原理
- 什么是Skill? Skill 是一个自包含的知识包,包含:
| 组件 | 说明 |
|---|---|
| Instructions | 详细指导(SKILL.md)中 |
| Scripts | 可选的可执行脚本 |
| References | 可选的参考文档 |
- 目录结构
my-skill/
- SKILL.md # 必需:带YAML 前置元数据的指令
- scripts/ # 可选:可执行脚本
- helper.py
- references/ #可选:参考文档
- guide.md
- SKILL.md 文件示例
---
name: code-review
description: 代码审查助手,提供风格检查和最佳实践
license: Apache-2.0
metadata:
version: "1.0.0"
author: your-name
---
# 代码审查技能
当审查代码质量、风格和最佳实践使用此技能
## 何时使用
- 用户请求代码审查
- 用户想改进代码质量
## 流程
1. 分析结构
2. 检查风格
3. 识别问题
4. 提供建议
核心作用
按需加载领域专业知识 不需要在系统消息内填满所有指令,Skills需要让我们将前置的知识组织成聚焦的包,AI Agent只需加载需要的内容,节省tokens和成本
可复用的知识包 创建一次,多个AI Agent可以共享使用
渐进式发现(懒加载)
1. 浏览-> AI Agent 在系统提示中看到技能摘要
2. 加载-> 任务分配时,AI Agent加载完整指令
3. 引用-> AI Agent按需访问详细文档
4. 执行->AI Agent可运行技能中的脚本
# 48- AI Agent系统中Memory机制万变不离其宗的核心功能有哪些?
AI Agent系统中Memory的增删改查是万变不离其宗的核心功能
- 通过同步和异步的方式添加记忆
- 通过同步和异步的方式获取记忆
- 通过同步和异步的方式删除记忆
- 通过同步和异步的方式更新记忆
在获取记忆的获取上,有如下策略
- last_n(最新N条)按照updated_at时间戳倒序排序,返回最新更新的记忆,适合获取最新信息
- first_n(最早N条):按updated_at时间戳正序排序,返回最早记忆,适合获取基础信息
- agentic(智能语义搜索):获取所有用户记忆,构建搜索提示(包含所有记忆的ID、内容和主题),LLM根据查询语义分析相关记忆,从原始记忆列表中提取匹配的记忆。