
 v8引擎
v8引擎
# 1. js引擎
JavaScript引擎分类:
- SpiderMonkey: 第一款JavaScript引擎,由BrenDan Eich开发(也就是JavaScript作者)
- Chakra: 微软开发,用于IE浏览器
- JavaScriptCore: WebKit中的JavaScript引擎,Apple公司开发
- V8: Google开发的强大JavaScript引擎,也帮助Chrome从众多浏览器中脱颖而出
# 2. V8引擎的原理
V8是用C++编写的Google开源高性能JavaScript和WebAssembly引擎,它用于Chrome和Node.js等. 它实现ECMAScript和WebAssembly,并在Windows7或更高版本,MacOs10.12+和使用x64,IA-32,ARM或MISP处理器的Linux系统上运行。
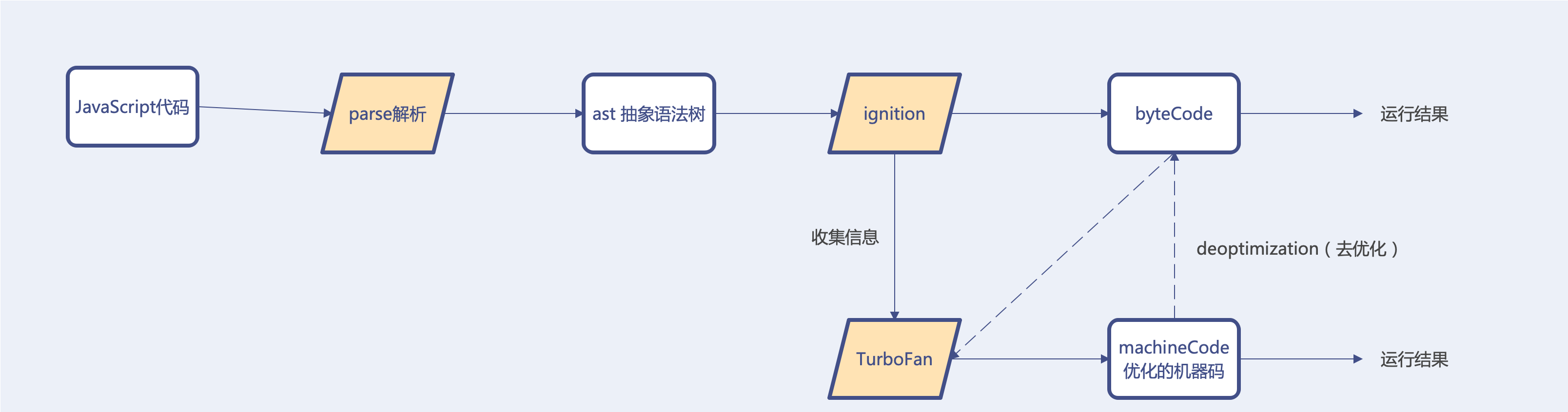
v8引擎通过Parse 进行词法分析,语法分析后转换成AST抽象语法树,再通过Ignition转换器将其转换成字节码。
# 3. V8引擎的架构
- Parse:模块会将JavaScript代码转换成AST(抽象语法树),这是因为解释器并不认识JavaScript代码(如果函数没有被调用,那么是不会被转换成AST的)
- Ignition:可以理解为解释器(转换器),将ast 转化为字节码,同时会收集TurboFan优化所需要的信息(比如函数参数的类型信息,有了类型才能进行真实的运算),如果函数只调用一次,Ignition会执行解释执行ByteCode;
- TurboFan:可以理解为编译器,可以将字节码编译为CPU可以直接执行的机器码;如果一个函数被多次调用,那么就会被标记为热点函数,那么就会经过TurboFan转换成优化的机器码,提高代码的执行性能
特殊场景:机器码被还原为ByteCode,后续执行函数中,函数类型发生了变化(比如sum函数原来执行的是number类型,后来执行变成了string类型),之前优化的机器码并不能正确的处理运算,就会逆向的转换成字节码
# 4. V8引擎的解析
V8引擎的解析图
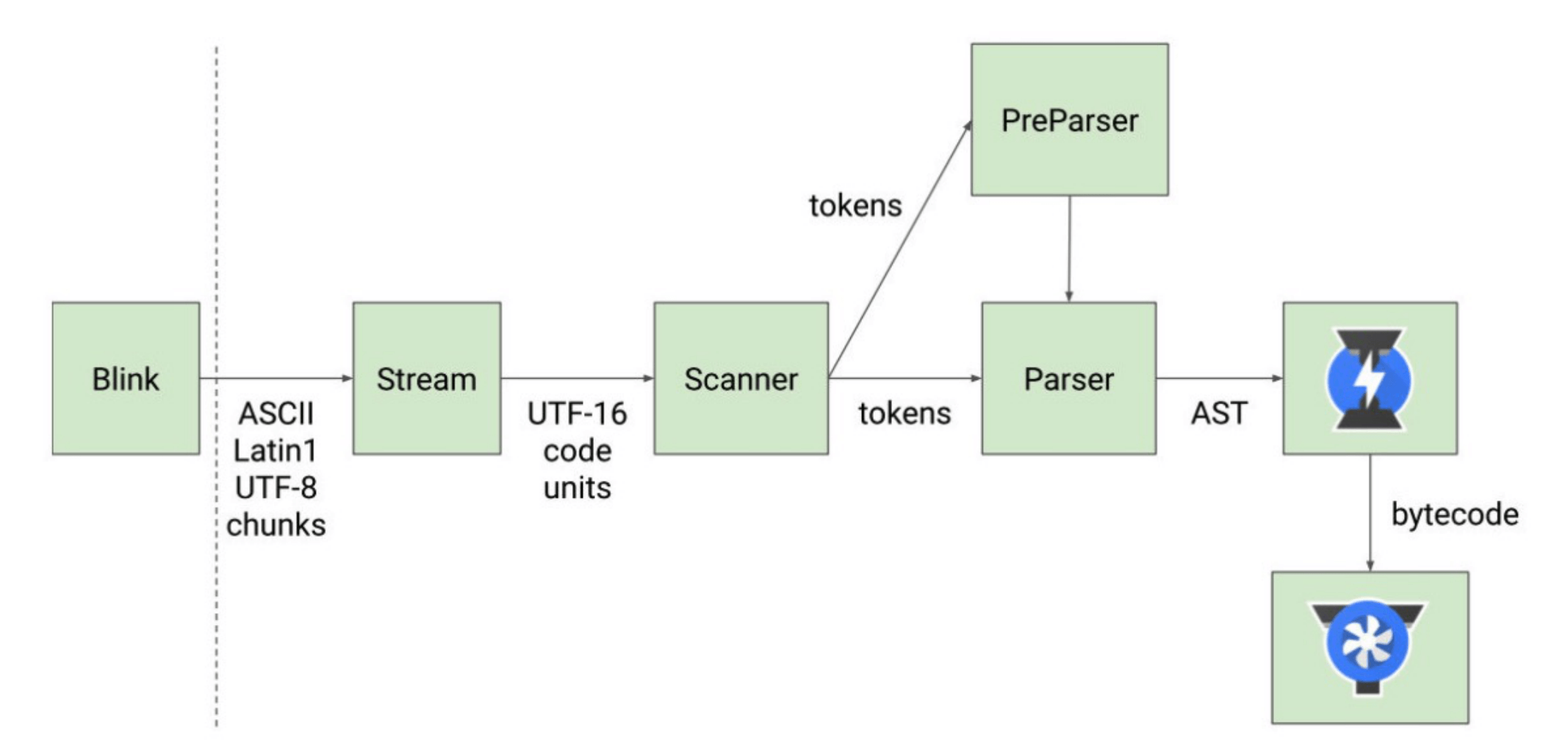
Blink(浏览器内核)将js代码交给V8引擎,Stream获取到源码进行编码转换
Scanner会进行词法分析(lexical analysis),词法分析会将代码转换成tokens
tokens会被转换成AST树,经过Parser和PreParser
- 3.1 Parser就是直接将tokens转成AST树架构
- 3.2 PreParser预解析,什么时候进行预解析呢? 存在不必要的函数会进行预解析。为了提高网页的运行效率,v8引擎通过Lazy Parsing(延迟解析),将不必要立即执行的函数进行预解析。
提示
Webkit 渲染引擎有一个优化,当渲染进程接收 HTML 文件字节流时,会先开启一个预解析线程,如果遇到 JavaScript 文件或者 CSS 文件,那么预解析线程会提前下载这些数据。当渲染进程接收 HTML 文件字节流时,会先开启一个预解析线程,如果遇到 JavaScript 文件或者 CSS 文件,那么预解析线程会提前下载这些数据。
- 生成AST树后,会被Ignition转成字节码(bytecode),之后的过程就是代码的执行
# 5. js代码执行过程
提示
- VO:Variable Object每一个执行上下文会被关联到一个变量对象称为AO
- GO:Global Object
- AO:Activation Object
- ESC:执行上下文栈(Execution Context Stack,简称ECS),它是用于执行代码的调用栈
- GEC:全局执行上下文(Global Execution Context) 全局的代码块为了执行构建的产物
- FEC:函数执行上下文(Functional Execution Context)
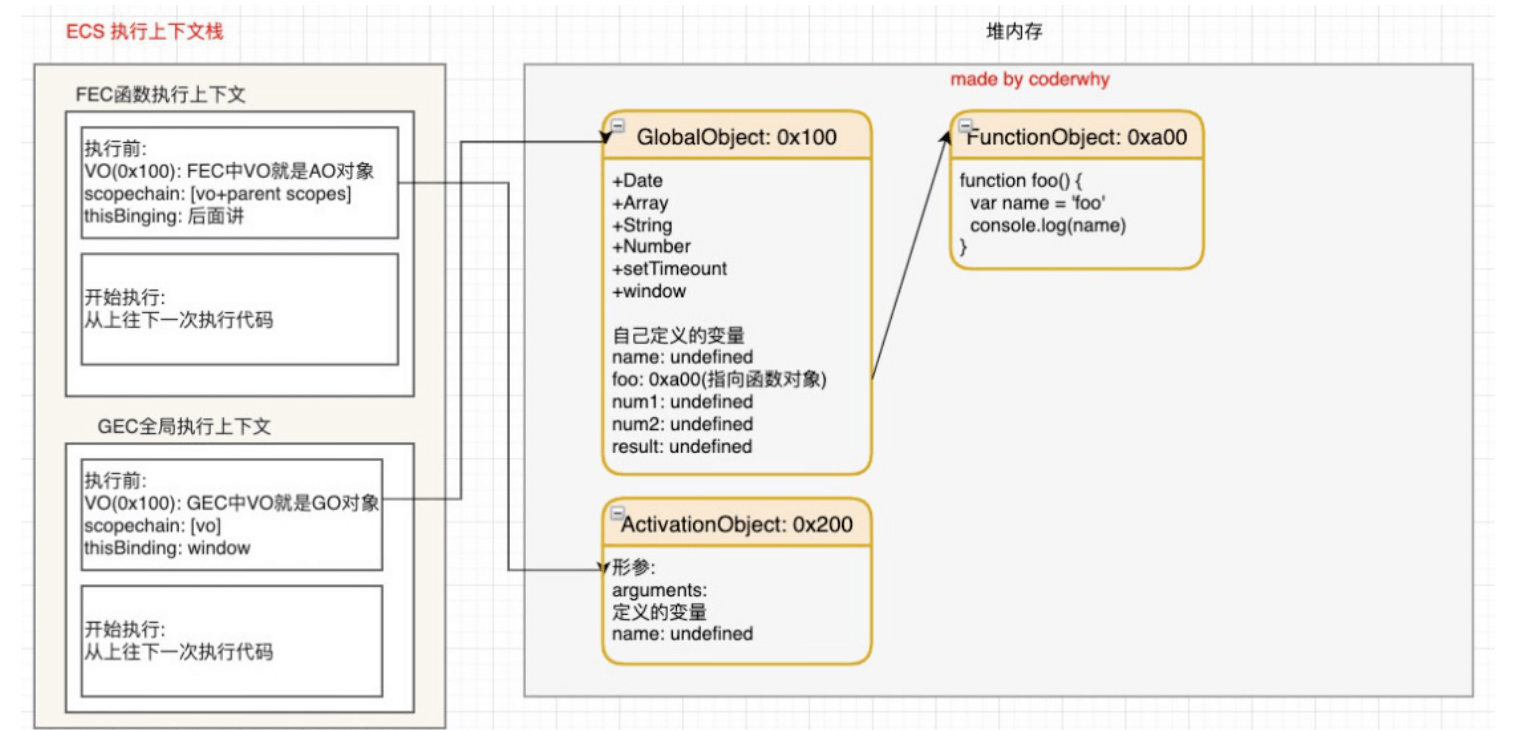
js引擎会在执行代码之前,在堆内存中创建一个全局对象:GO
- 该对象所有的作用域(scope)都可以访问
- 里面会包含**Date,Array,String,Number,setTimeout,setInterval等等;
- window属性指向自己
// GlobalObject
var globalObject = {
String: "类",
Date: "类",
setTimeout: "函数",
// ....
window: globalObject(指向本身),
name: undefined,
num1: undefined,
num2: undefined,
result: undefined
}
# 执行上下文栈(调用栈)
js引擎内部有一个执行上下文栈(Execution Context Stack,简称ECS),它是用于执行代码(全局的代码块)的调用栈。
全局的代码块为了执行会构建一个Global Execution Context(GEC) GEC会被放入到ECS中执行。
GEC被放入到ECS中里面包含两部分内容:
- 在代码执行前,parser转成AST的过程中,会将全局定义的变量,函数等加入到GO中,但是并不会赋值(undefined) 这个过程也称之为变量的作用域提升(hoisting)
- 在代码执行中,对变量赋值,或者执行其他的函数。
# 执行函数
在执行的过程中执行到一个函数时,就会根据函数体创建一个函数执行上下文(Functional Execution Context/FEC),并且压入到EC Stack中.
FEC中包含三部分内容:
- 在解析函数成为AST树结构时,会创建一个Activation Object(AO): AO中包含形参,arguments,函数定义和指向函数对象,定义的变量
- 作用域链,由VO(在函数中就是AO对象)和父级VO组成,查找时会一层层查找
- this绑定的值
# 6. js设计思想
# 快属性和慢属性
V8 中命名属性有三种的不同存储方式:对象内属性(in-object)、快属性(fast)和慢属性(slow)。
在 V8 实现对象存储时,并没有完全采用字典的存储方式,这主要是出于性能的考量。因为字典是非线性的数据结构,查询效率会低于线性的数据结构,V8 为了提升存储和查找效率,采用了一套复杂的存储策略。
# 常规属性 (properties) 和排序属性 (element)
function Foo() {
this[100] = 'test-100'
this[1] = 'test-1'
this["B"] = 'bar-B'
this[50] = 'test-50'
this[9] = 'test-9'
this[8] = 'test-8'
this[3] = 'test-3'
this[5] = 'test-5'
this["A"] = 'bar-A'
this["C"] = 'bar-C'
}
var bar = new Foo()
for(key in bar){
console.log(`index:${key} value:${bar[key]}`)
}
- 设置的数字属性被最先打印出来了,并且是按照数字大小的顺序打印的;
- 设置的字符串属性依然是按照之前的设置顺序打印的,比如我们是按照 B、A、C 的顺序设置的,打印出来依然是这个顺序。
index:1 value:test-1
index:3 value:test-3
index:5 value:test-5
index:8 value:test-8
index:9 value:test-9
index:50 value:test-50
index:100 value:test-100
index:B value:bar-B
index:A value:bar-A
index:C value:bar-C
因为在 ECMAScript 规范中定义了数字属性应该按照索引值大小升序排列,字符串属性根据创建时的顺序排列。
把对象中的数字属性称为排序属性,在 V8 中被称为 elements,字符串属性就被称为常规属性,在 V8 中被称为 properties。
# 快属性和慢属性
将不同的属性分别保存到 elements 属性和 properties 属性中,无疑简化了程序的复杂度,但是在查找元素时,却多了一步操作,比如执行 bar.B这个语句来查找 B 的属性值,那么在 V8 会先查找出 properties 属性所指向的对象 properties,然后再在 properties 对象中查找 B 属性,这种方式在查找过程中增加了一步操作,因此会影响到元素的查找效率。
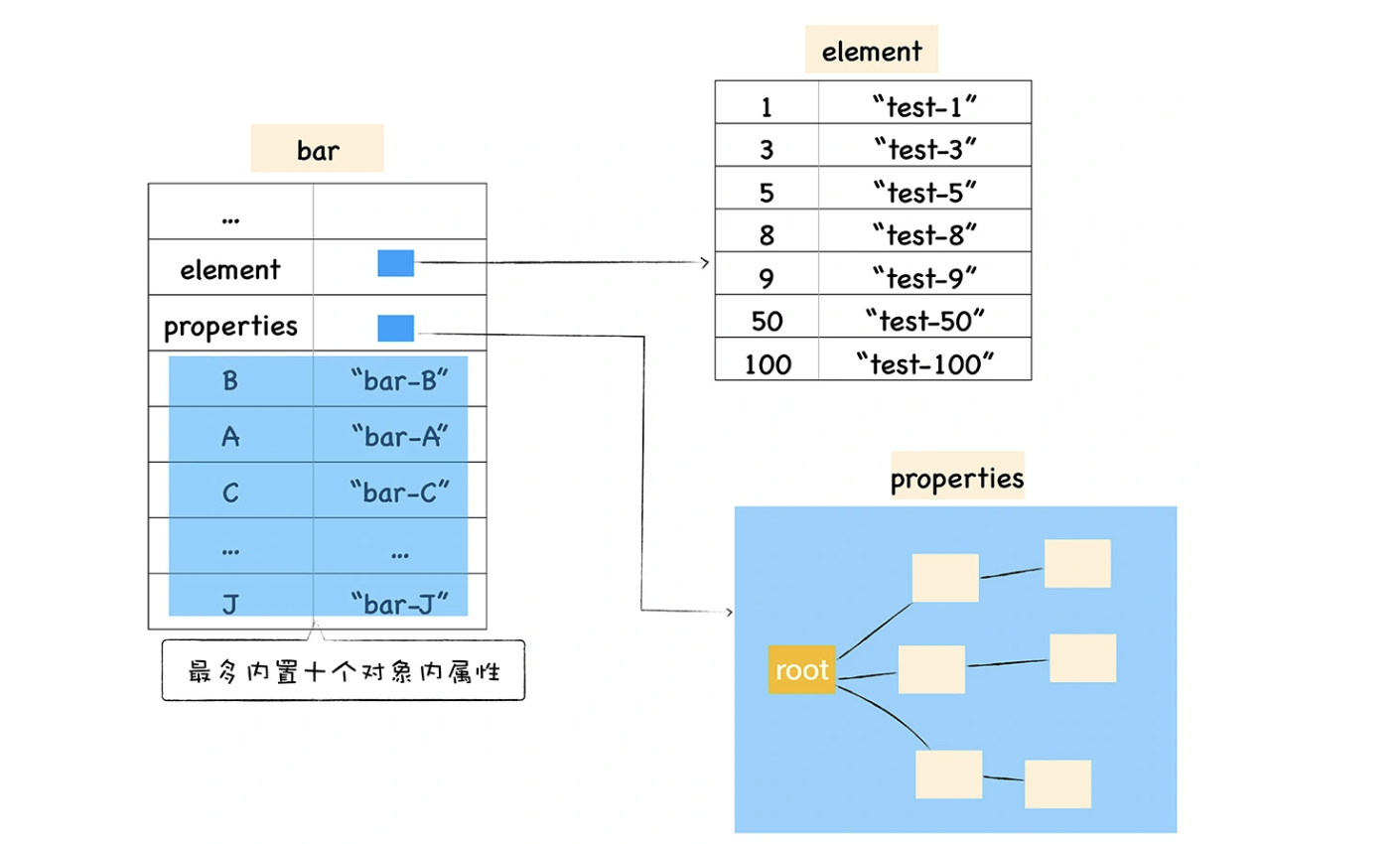
基于这个原因,V8 采取了一个权衡的策略以加快查找属性的效率,这个策略是将部分常规属性直接存储到对象本身,我们把这称为对象内属性 (in-object properties)。对象在内存中的展现形式你可以参看下图:
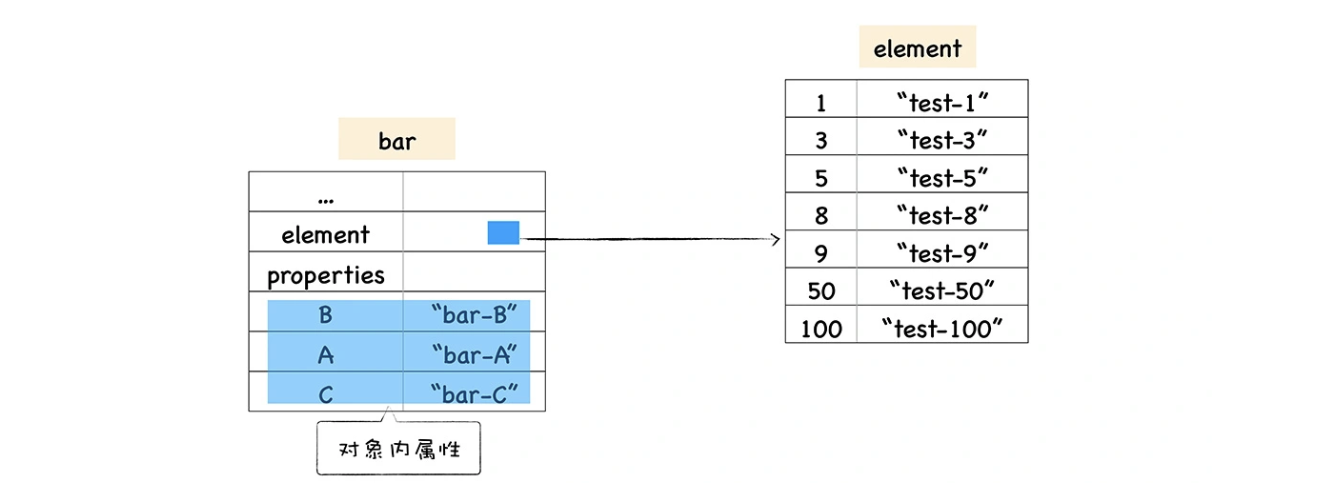
采用对象内属性之后,常规属性就被保存到 bar 对象本身了,这样当再次使用bar.B来查找 B 的属性值时,V8 就可以直接从 bar 对象本身去获取该值就可以了,这种方式减少查找属性值的步骤,增加了查找效率。
不过对象内属性的数量是固定的,默认是 10个,如果添加的属性超出了对象分配的空间,则它们将被保存在常规属性存储中。虽然属性存储多了一层间接层,但可以自由地扩容。
通常,我们将保存在线性数据结构中的属性称之为“快属性”,因为线性数据结构中只需要通过索引即可以访问到属性,虽然访问线性结构的速度快,但是如果从线性结构中添加或者删除大量的属性时,则执行效率会非常低,这主要因为会产生大量时间和内存开销。
因此,如果一个对象的属性过多时,V8 就会采取另外一种存储策略,那就是“慢属性”策略,但慢属性的对象内部会有独立的非线性数据结构 (词典) 作为属性存储容器。所有的属性元信息不再是线性存储的,而是直接保存在属性字典中。
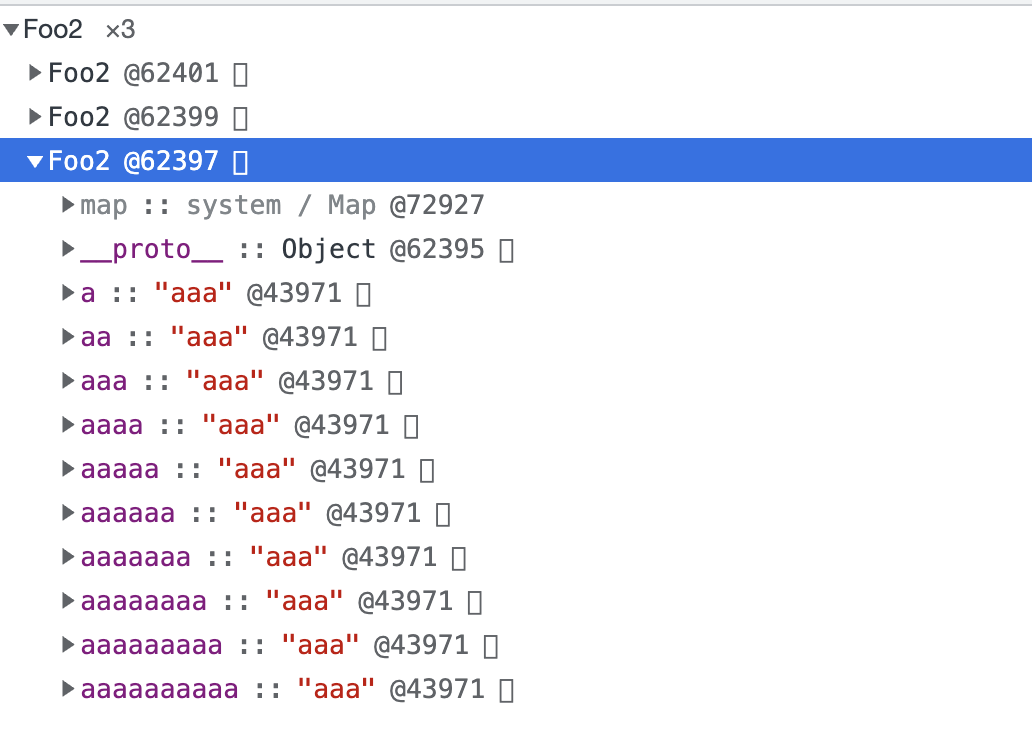
function Foo2() {}
var a = new Foo2()
var b = new Foo2()
var c = new Foo2()
for (var i = 0; i < 10; i ++) {
a[new Array(i+2).join('a')] = 'aaa'
}
for (var i = 0; i < 12; i ++) {
b[new Array(i+2).join('b')] = 'bbb'
}
for (var i = 0; i < 30; i ++) {
c[new Array(i+2).join('c')] = 'ccc'
}
分别会以对象内属性、对象内属性 + 快属性、慢属性三种方式存储。
# 对象内属性:
# 快属性:
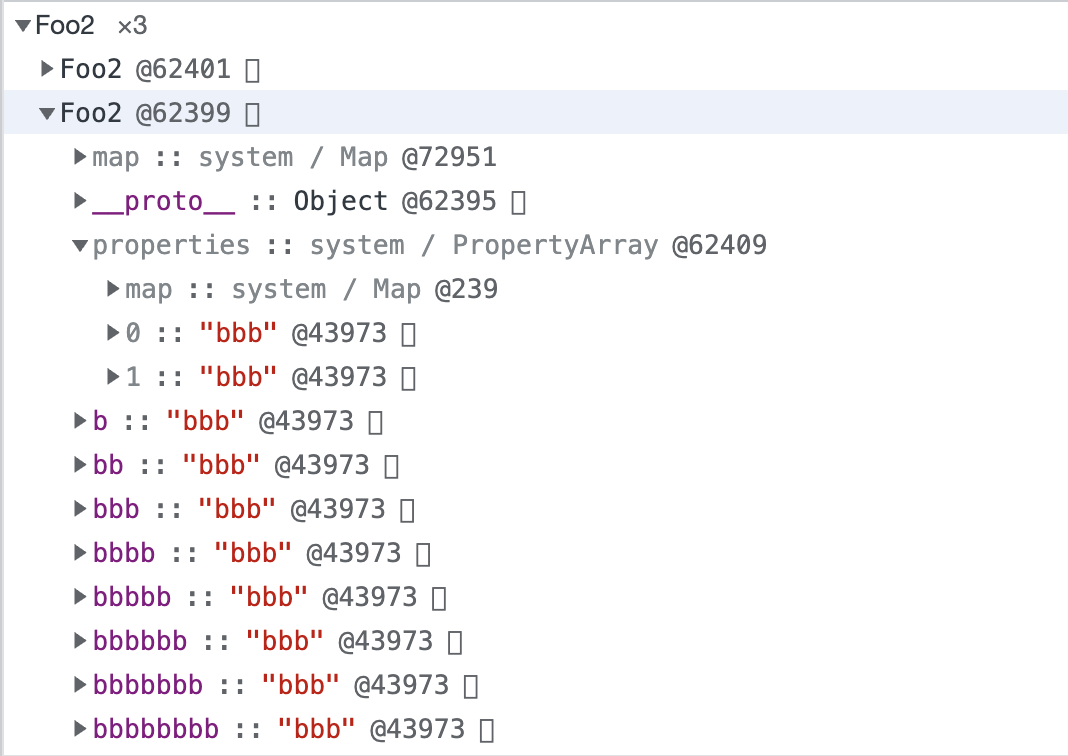
a 和 b。从某种程度上讲,对象内属性和快属性实际上是一致的。只不过,对象内属性是在对象创建时就固定分配的,空间有限。对象内属性的数量固定为十个,且这十个空间大小相同(可以理解为十个指针)。当对象内属性放满之后,会以快属性的方式,在 properties 下按创建顺序存放。相较于对象内属性,快属性需要额外多一次 properties 的寻址时间,之后便是与对象内属性一致的线性查找。
# 慢属性:
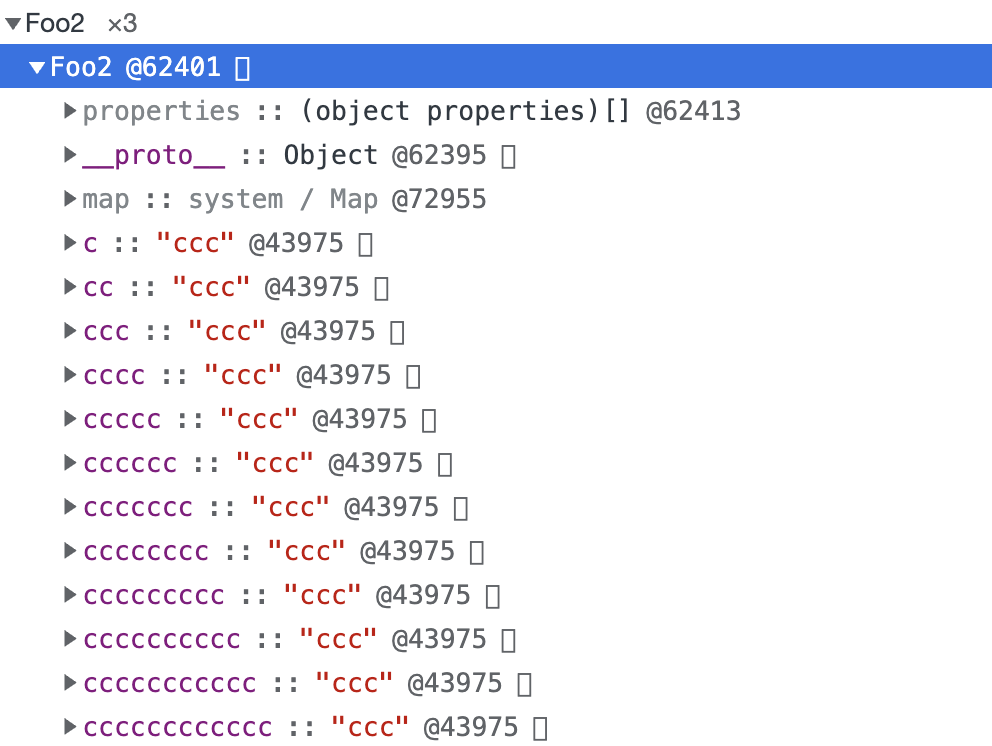 和 b (快属性)相比,
和 b (快属性)相比,properties 中的索引变成了毫无规律的数,意味着这个对象已经变成了哈希存取结构了。
为什么不建议使用 delete
使用delete删除属性: 如果删除属性在线性结构中,删除后需要移动元素,开销较大,而且可能需要将慢属性重排到快属性。 如果删除属性在properties对象中,查找开销较大。
# 函数表达式
函数表达式:
foo()
var foo = function ()
{
console.log('foo')
}
函数声明:
foo()
function foo()
{
console.log('foo')
}
在编译阶段,如果解析到函数声明,那么 V8 会将这个函数声明转换为内存中的函数对象,并将其放到作用域中。同样,如果解析到了某个变量声明,也会将其放到作用域中,但是会将其值设置为 undefined,表示该变量还未被使用。
然后在 V8 执行阶段,如果使用了某个变量,或者调用了某个函数,那么 V8 便会去作用域查找相关内容。
函数表达式与函数声明区别:
函数表达式是在表达式语句中使用 function 的,最典型的表达式是“a=b”这种形式,因为函数也是一个对象,我们把“a = function (){}”这种方式称为函数表达式;
在函数表达式中,可以省略函数名称,从而创建匿名函数(anonymous functions);
一个函数表达式可以被用作一个即时调用的函数表达式——IIFE(Immediately Invoked Function Expression)。
# 立即调用的函数表达式(IIFE)
在编译阶段,V8 并不会处理函数表达式,而 JavaScript 中的立即函数调用表达式正是使用了这个特性来实现了非常广泛的应用。
括号里面是一个表达式,整个语句也是一个表达式,最终输出 3。
(a=3)
如果在小括号里面放上一段函数的定义,如下所示:
(function () {
//statements
})
因为小括号之间存放的必须是表达式,所以如果在小阔号里面定义一个函数,那么 V8 就会把这个函数看成是函数表达式,执行时它会返回一个函数对象。
存放在括号里面的函数便是一个函数表达式,它会返回一个函数对象,如果我直接在表达式后面加上调用的括号,这就称为立即调用函数表达式(IIFE),比如下面代码:
(function ()
{ //statements
})()
因为函数立即表达式也是一个表达式,所以 V8 在编译阶段,并不会为该表达式创建函数对象。这样的一个好处就是不会污染环境,函数和函数内部的变量都不会被其他部分的代码访问到。
# 7. 垃圾回收
JavaScript 中的数据是如何存储?
- 原始数据类型是存储在栈空间中的,引用类型的数据是存储在堆空间中的。
# 栈垃圾回收:
当函数执行结束,JS引擎通过向下移动ESP(extended stack pointer)指针(记录调用栈当前执行状态的指针),来销毁该函数保存在栈中的执行上下文(变量环境、词法环境、this、outer)。
# 堆垃圾回收:
# 代际假说
特点:
- 1、大部分对象存活时间很短
- 2、不被销毁的对象,会活的更久
分类:
V8 中会把堆分为
新生代和老生代两个区域。
新生代和老生代划分区别:
时间上:新生代中存放的是生存时间短的对象,老生代中存放的生存时间久的对象,占用空间大。
容量上:新生区通常只支持 1~8M 的容量,而老生区支持的容量就大很多了。对于这两块区域,V8 分别使用两个不同的垃圾回收器,以便更高效地实施垃圾回收。
副垃圾回收器,主要负责新生代的垃圾回收。
主垃圾回收器,主要负责老生代的垃圾回收。
# 垃圾回收器的工作流程
标记:标记空间中活动对象和非活动对象。所谓活动对象就是还在使用的对象,非活动对象就是可以进行垃圾回收的对象(标记阶段就是从一组根元素开始,递归遍历这组根元素,在这个遍历过程中,能到达的元素称为活动对象,没有到达的元素就可以判断为垃圾数据)
回收非活动对象所占据的内存。其实就是在所有的标记完成之后,统一清理内存中所有被标记为可回收的对象
内存整理:回收对象后,内存中就会存在大量不连续空间,我们把这些不连续的内存空间称为内存碎片。当内存中出现了大量的内存碎片之后,如果需要分配较大连续内存的时候,就有可能出现内存不足的情况。所以最后一步需要整理这些内存碎片,但这步其实是可选的,因为有的垃圾回收器不会产生内存碎片。
# 副垃圾回收器
功能:
- 副垃圾回收器主要负责新生区的垃圾回收。而通常情况下,大多数小的对象都会被分配到新生区。
新生代中用 Scavenge 算法来处理。
Scavenge 算法,是把新生代空间对半划分为两个区域,一半是对象区域,一半是空闲区域,如下图所示:
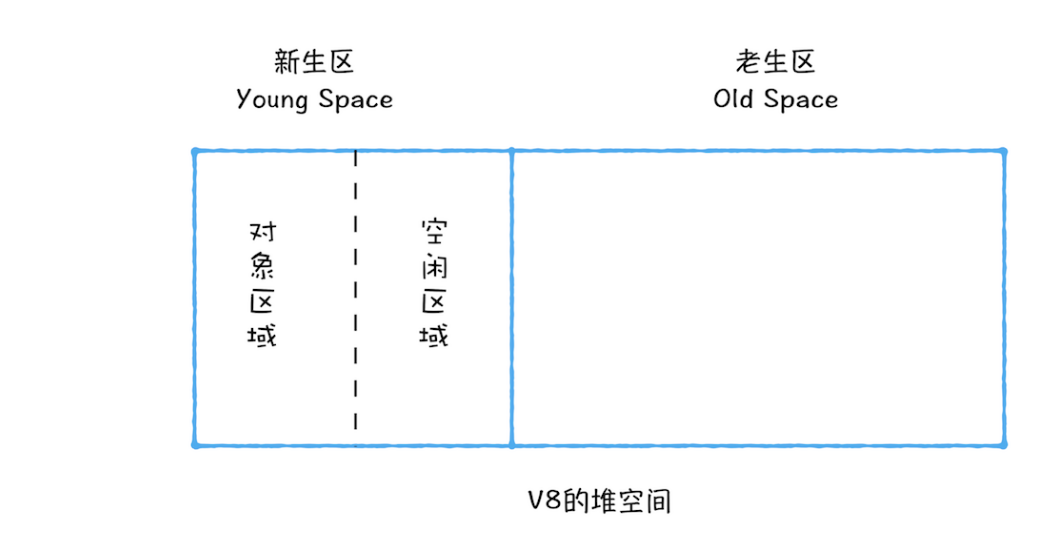
新加入的对象都会存放到对象区域,当对象区域快被写满时,就需要执行一次垃圾清理操作。
在垃圾回收过程中,首先要对对象区域中的垃圾做标记;标记完成之后,就进入垃圾清理阶段,副垃圾回收器会把这些存活的对象复制到空闲区域中,同时它还会把这些对象有序地排列起来,所以这个复制过程,也就相当于完成了内存整理操作,复制后空闲区域就没有内存碎片了。
完成复制后,对象区域与空闲区域进行角色翻转,也就是原来的对象区域变成空闲区域,原来的空闲区域变成了对象区域。这样就完成了垃圾对象的回收操作,同时这种角色翻转的操作还能让新生代中的这两块区域无限重复使用下去。
新生代只有1-8M,是故意设置这么小的。新生代设置大了,一次垃圾回收的时间就会变长。
由于新生代中采用的 Scavenge 算法,所以每次执行清理操作时,都需要将存活的对象从对象区域复制到空闲区域。但复制操作需要时间成本,如果新生区空间设置得太大了,那么每次清理的时间就会过久,所以为了执行效率,一般新生区的空间会被设置得比较小。
正是因为新生区的空间不大,所以很容易被存活的对象装满整个区域。为了解决这个问题,JavaScript 引擎采用了对象晋升策略,也就是经过两次垃圾回收依然还存活的对象,会被移动到老生区中。
# 主垃圾回收器
主垃圾回收器主要负责老生区中的垃圾回收。除了新生区中晋升的对象,一些大的对象会直接被分配到老生区。
因此老生区中的对象有两个特点,一个是对象占用空间大,另一个是对象存活时间长。
由于老生区的对象比较大,若要在老生区中使用 Scavenge 算法进行垃圾回收,复制这些大的对象将会花费比较多的时间,从而导致回收执行效率不高,同时还会浪费一半的空间。因而,主垃圾回收器是采用标记 - 清除(Mark-Sweep)的算法进行垃圾回收的。下面我们来看看该算法是如何工作的。
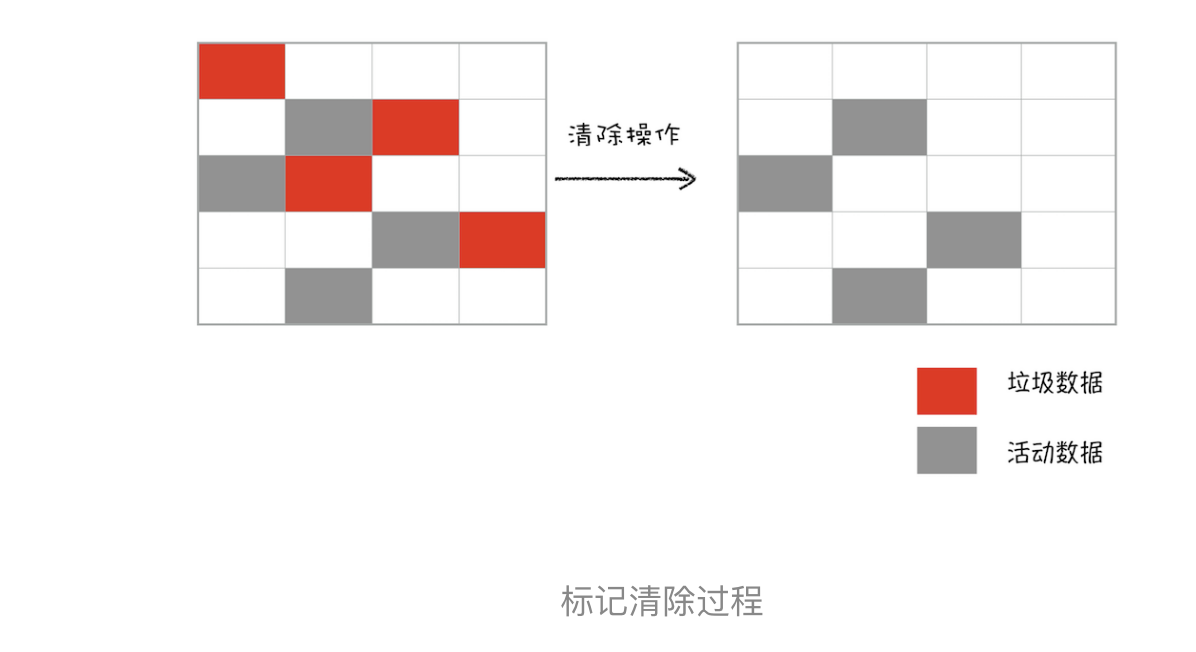
首先是标记过程阶段。标记阶段就是从一组根元素开始,递归遍历这组根元素,在这个遍历过程中,能到达的元素称为活动对象,没有到达的元素就可以判断为垃圾数据。
接下来就是垃圾的清除过程。它和副垃圾回收器的垃圾清除过程完全不同,可以理解这个过程是清除掉红色标记数据的过程,可参考下图大致理解下其清除过程:
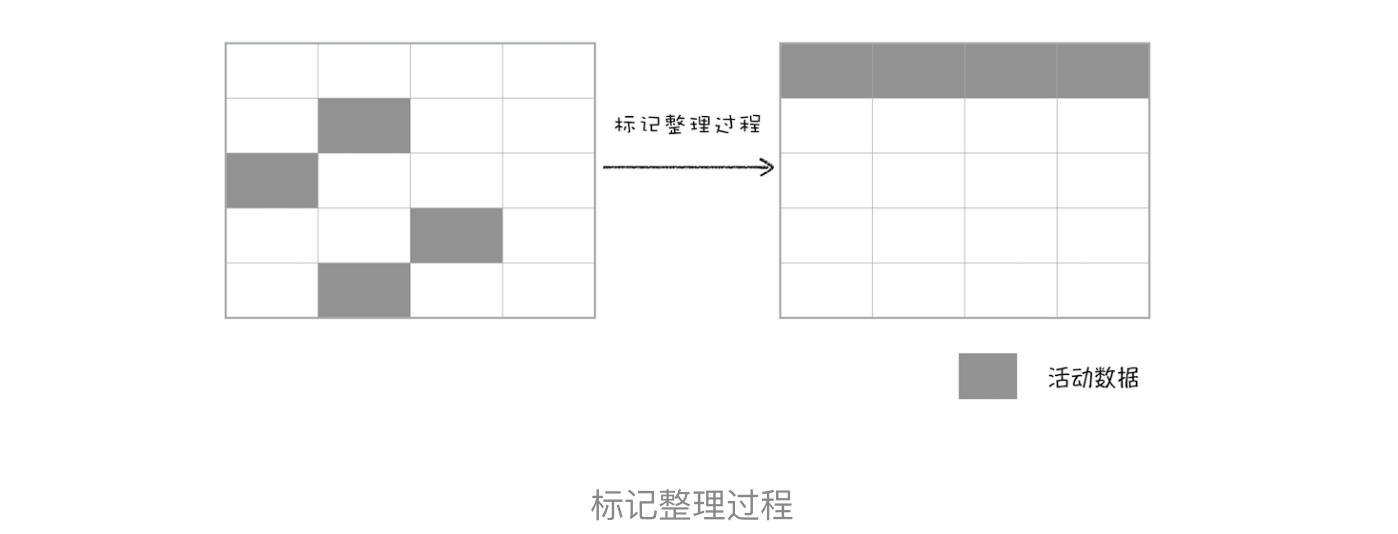
对一块内存多次执行标记 - 清除算法后,会产生大量不连续的内存碎片。而碎片过多会导致大对象无法分配到足够的连续内存,于是又产生了另外一种算法——标记 - 整理(Mark-Compact),这个标记过程仍然与标记 - 清除算法里的是一样的,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存
# 全停顿
由于 JavaScript 是运行在主线程之上的,一旦执行垃圾回收算法,都需要将正在执行的 JavaScript 脚本暂停下来,待垃圾回收完毕后再恢复脚本执行。我们把这种行为叫做全停顿(Stop-The-World)。
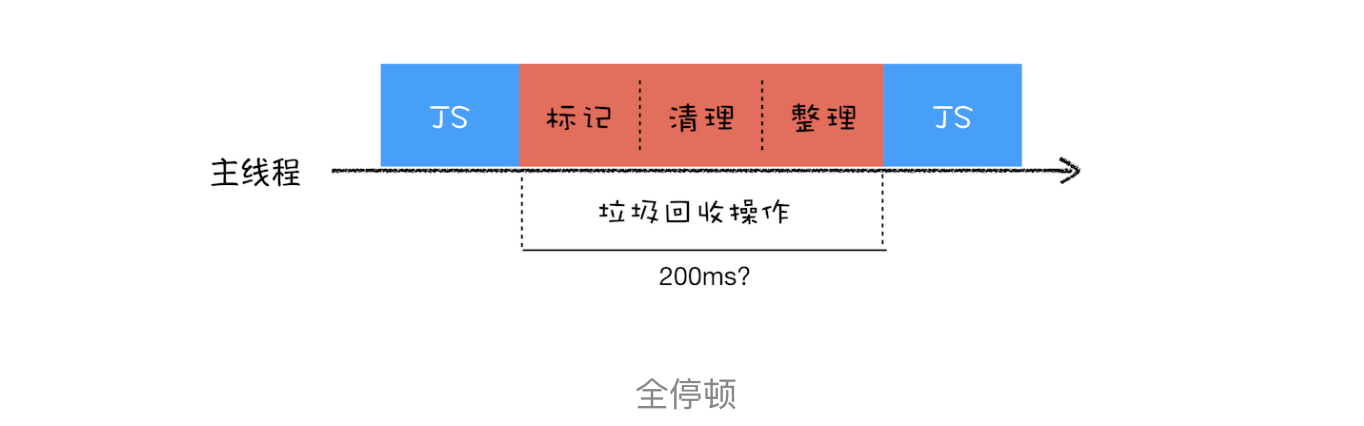
在 V8 新生代的垃圾回收中,因其空间较小,且存活对象较少,所以全停顿的影响不大,但老生代就不一样了。如果在执行垃圾回收的过程中,占用主线程时间过久,就像上面图片展示的那样,花费了 200 毫秒,在这 200 毫秒内,主线程是不能做其他事情的。比如页面正在执行一个 JavaScript 动画,因为垃圾回收器在工作,就会导致这个动画在这 200 毫秒内无法执行的,这将会造成页面的卡顿现象。
# 增量标记
为了降低老生代的垃圾回收而造成的卡顿,V8 将标记过程分为一个个的子标记过程,同时让垃圾回收标记和 JavaScript 应用逻辑交替进行,直到标记阶段完成,我们把这个算法称为增量标记(Incremental Marking)算法。如下图所示:
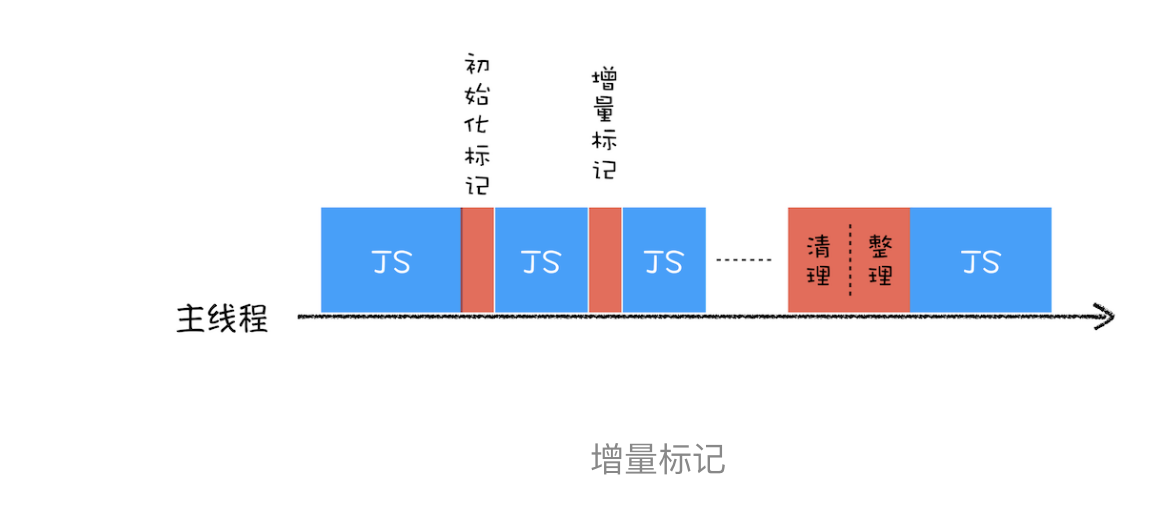
使用增量标记算法,可以把一个完整的垃圾回收任务拆分为很多小的任务,这些小的任务执行时间比较短,可以穿插在其他的 JavaScript 任务中间执行,这样当执行上述动画效果时,就不会让用户因为垃圾回收任务而感受到页面的卡顿了。