
 模块机制
模块机制
# 01. CommonJS 规范
# javascript 缺陷:
- 没有模块系统
- 标准库较少: ECMAScript 仅定义了部分核心库,对于文件系统,I/O 流等常见需求没有标准的 API。
- 没有标准接口: 在 JavaScript 中,几乎没有定义过如 web 服务器或者数据库之类的统一标准。
- 缺乏包管理系统:javascript 没有自动加载和安装的能力。
Node 借鉴 CommonJs 的 Module 规范实现了一套非常易用的模块系统,NPM 对 Package 规范的完好支持使得 Node 应用在开发过程中事半功倍。
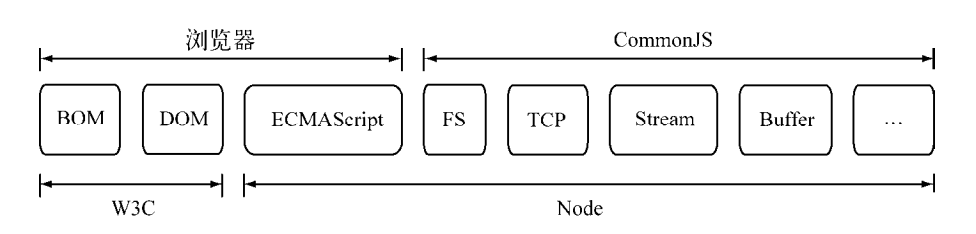
# CommonJs 的模块规范
主要分为:模块引用,模块定义,模块标识 3 部分。
- 模块引用
在 CommonJs 规范中,存在 reuqire()方法,这个方法收模块标识,以此引入一个模块的 api 到当前上下文中。
var math = reuqire('math');
- 模块定义
在模块中,上下文提供 require()方法来引入外部模块。对于引入的功能,上下文还提供了
exports对象用于导出当前模块的方法或者变量,它是唯一的导出入口。在模块中,还存在一个module对象,它代表模块本身,而exports是module的属性。在 Node 中,一个文件就是模块,将方法挂载在exports对象上作为属性即可定义导出的方式。
// math.js
exports.add = function() {
var sum = 0,
i = 0 ,
args = arguments,
l = args.length;
while(i < l) {
sum += args[i++];
}
return sum;
}
var math = require('./common');
console.log(math.add(10));
- 模块标识
模块标识其实就是传递给 require()方法的参数,它必须是符合小驼峰命名的字符串,或者以./..开头的相对路径,或者绝对路径,可以没有文件后缀 js
如下:每个模块具有独立的空间,互不干扰
CommonJs 构建的这套模块导出和引入机制使得用户完全不必考虑变量污染,命名空间等方案。
# 02. Node 模块实现
在 node 中引入模块需要经历以下三个步骤:
- 路径分析
- 文件定位
- 编译执行
在 Node 中,模块分为两类,一种是 Node 提供的模块(核心模块),另一类是用户编写的模块(文件模块)
- 核心模块:在 Node 源代码的编译过程中,编译进了二进制执行文件。在 Node 进程启动时,部分核心模块被直接加载进内存中,所以这部分核心模块,文件定位和编译执行步骤省略,在路径分析中优先判断,加载速度最快。
- 文件模块:是在运行时动态加载,需要完整的路径分析,文件定位,编译执行过程,速度比核心模块加载慢。
加载过程:
# 优先从缓存加载
与前端浏览器会缓存静态脚本文件用来提高性能一样,NodeJs 对引入过的模块都会进行缓存,用来减少二次引入时的开销。区别在于:浏览器仅缓存文件,node 缓存的是编译和执行之后的对象。 无论是核心模块还是文件模块,require()方法对于相同模块的二次加载都会采用缓存优先的方式,这是第一优先级。不同之处就是核心模块的缓存检查会先与文件模块的缓存检查。
# 路径分析与文件定位
对于不同的标识符,模块的查找和定位有不同程度上的差异。
# 模块标识符分析
require()方法接受一个标识符作为参数。 模块标识符主要分为以下几类:
- 核心模块:如 http, fs, path 等
- .或.. 开始的相对路径文件模块
- 以/开始的绝对路径文件模块
- 非路径形式的文件模块,如自定义的 connect 模块
核心模块: 核心模块的优先级仅次于缓存模块,它在 node 的源代码编译过程中已经编译称二进制代码,其加载过程最快。
提示
如果加载一个与核心模块标识符一样的自定义模块,是不会成功的。比如选择一个不同的标识符或者更换路径的方式。
路径形式的文件模块 以.、..、/开始的标识符,都是被当作文件模块处理的。在分析路径模块时,require()方法会将路径转为真实路径,并以真实路径作为索引,将编译执行后的结果存入缓存中,以使二次加载时更快。
由于文件模块给 Node 指明了确切的文件地址,所以在查找过程中节约大量时间,加载速度小于核心模块。
- 自定义模块
自定义模块指的是非核心模块,也不是路径形式的标识符,它是一种特殊的文件模块,可能是一个文件或包的形式,这类模式的查找最费时,也是所有方法中最慢的。
模块路径
模块路径是 Node 在定位文件模块的具体文件时制定的查找策略,具体表现为:一个路径组成的数组。
console.log(module.paths)
// 输出结果
[
'/Users/wsh/github/node-demo/node_modules',
'/Users/wsh/github/node_modules',
'/Users/wsh/node_modules',
'/Users/node_modules',
'/node_modules'
]
模块路径的生成规则:
- 当前文件目录下的 node_modules 目录
- 父目录下的 node_modules 目录
- 父目录下的父目录下的 node_modules 目录
- 沿路径向上逐级递归,直到根目录下的 node_modules 目录
生成方式与 JavaScript 的原型链或者作用域的查找方式类似,在加载过程中,Node 会逐步尝试模块路径下的路径,直到找到目标文件为止。当文件的路径越深,模块查找耗时会越多,这也是自定义模块的加载速度最慢的原因。
# 文件定位
从缓存加载的优化策略使得二次引入时不需要路径分析,文件定位和编译执行的过程,大大提高了再次加载模块时的效率。
在文件定位过程中,需要注意以下几点
- 文件扩展名分析: require()在分析标识符的过程中,会出现标识符不包含文件扩展名的情况,CommonJs 模块规范允许在标识符中不好包括文件扩展名,这个时候,nodejs 会以此按照 js,json,.node 的次序补充扩展名,依次尝试。
在尝试过程中,需要调用fs模块同步阻塞判断文件是否存在。因为 node 是单线程的,所以这里是一个会引起性能问题的地方。所以我们在加载 json 和 node 文件时。传递给 require()的标识符上带上扩展命,会加快一点速度。另外就是:同步配合缓存,大幅度缓解 node 单线程中阻塞式调用的缺点。 2. 目录分析和包
在分析标识符的过程中,require()通过分析文件扩展名之后,可能没有查找到对应的文件,但是却得到目录,这个在引入自定义分析模块和逐个模块路径进行查找时经常出现,此时 Node 会将目录当作个包来处理。
在这个分析过程中,Node 对 CommonJs 包规范进行了一定程度的支持。首先,Node 在当前目录下查找 package.json,通过 JSON.parse()解析出包描述对象,从中取出 main 属性指定的文件名进行定位。如果文件名缺少扩展名,将会进入扩展名分析的步骤。
如果 main 属性指定的文件名错误,或者咩有 package.json 文件,Node 会将 index 当作默认文件名,然后依次查找 index.js, index.json, index.node。
如果在目录分析的过程中没有定位成功任何文件,则自定义模块进入下一个模块路径进行查找。如果模块路径数组都被遍历完,依然没有查找到目标文件,则会抛出查找失败的 error。
# 模块编译
在 node 中,每个文件模块都是一个对象,定义如下:
function Module(id, parent) {
this.id = id;
this.exports = {};
this.parent = parent;
if (parent && parent.children) {
parent.children.push(this);
}
this.filename = null;
this.loaded = false;
this.children = [];
}
编译和执行是引入文件模块的最后一个阶段。定位到具体文件后,Node 会新建一个模块对象,然后根据路径载入并编译。对于不同的文件扩展名,其载入方式也有所不同。具体如下:
- .js 文件:通过 fs 模块同步读取文件后编译执行
- .node 文件: 用 c/c++编写的扩展文件,通过 dlopen()方法加载最后编译生成的文件。
- .json 文件:通过 fs 模块同步读取文件后,用 JSON.parse()解析返回结果
- 其余文件扩展名:都被当作.js 文件载入
每一个·编译成功的模块都会将其文件路径作为索引缓存在 Module._cache 对象上,以提高二次引入的性能。
根据不同的文件扩展名,Node 会采取不同的读取方式。 json 文件调用:
Module._extensions['.json'] = function(module, filename) {
var content = NativeModule.require('fs').readFileSync(filename, 'utf8');
try {
module.exports = JSON.parse(stripBOM(content));
} catch(error) {
error.mesage = filename + ':' + err.message;
throw err;
}
}
Module._extensions 会被赋值给 require()的 extension 属性,所以通过在代码中访问 require.extensions 可以知道系统中已有的扩展加载方式。
{
'.js': [Function (anonymous)],
'.json': [Function (anonymous)],
'.node': [Function (anonymous)]
}
require.extensions (新增于: v0.3.0,弃用于: v0.10.6)。官方期望可以通过其他一些 Node.js 程序加载模块,或者提前将它们编译为 JavaScript。这样可以不将繁琐的编译加载等过程引入到 Node 的执行过程中。
在确定文件的扩展名后,Node 将调用具体的编译方式来将文件执行后返回给调用者。
# Javascript 模块的编译
在 CommonJs 模块规范中,每个模块文件中存在着 require, exports, module 这三个变量,但是在模块中没有定义,从何而来?在 NodeAPI 文档中,每个模块还有**fileName, **dirname 这两个变量的存在,又从何而来? 如果我们直接定义模块的过程存在浏览器端,会存在污染全局变量的情况。
在 Node 编译过程中,NodeJs 对过去的文件进行了头尾包装。:
(function(exports, require, module, __filename, __dirname) {
exports.area = function(radius) {
return Math.PI * radius * radius;
}
})
这样每个模块文件之间都进行了作用域隔离。包装以后的代码会通过 vm 原生模块的 runInThisContenxt() 方法执行(类似 eval,只是具有明确上下文,不会污染全局),返回一个具体的 function 对象。 最后将当前模块对象的 exports 属性,require(),module(模块对象自身),以及在文件定位中得到的完整文件路径和文件目录作为参数传递给这个 function()执行。
这就是这些变量没有定义却在每个模块文件中存在的原因。在执行后,模块的 exports 属性被返回给了调用方。 exports 属性上的任何方法和属性都可以被外部调用,但是在模块中其余变量或属性不可直接被调用。
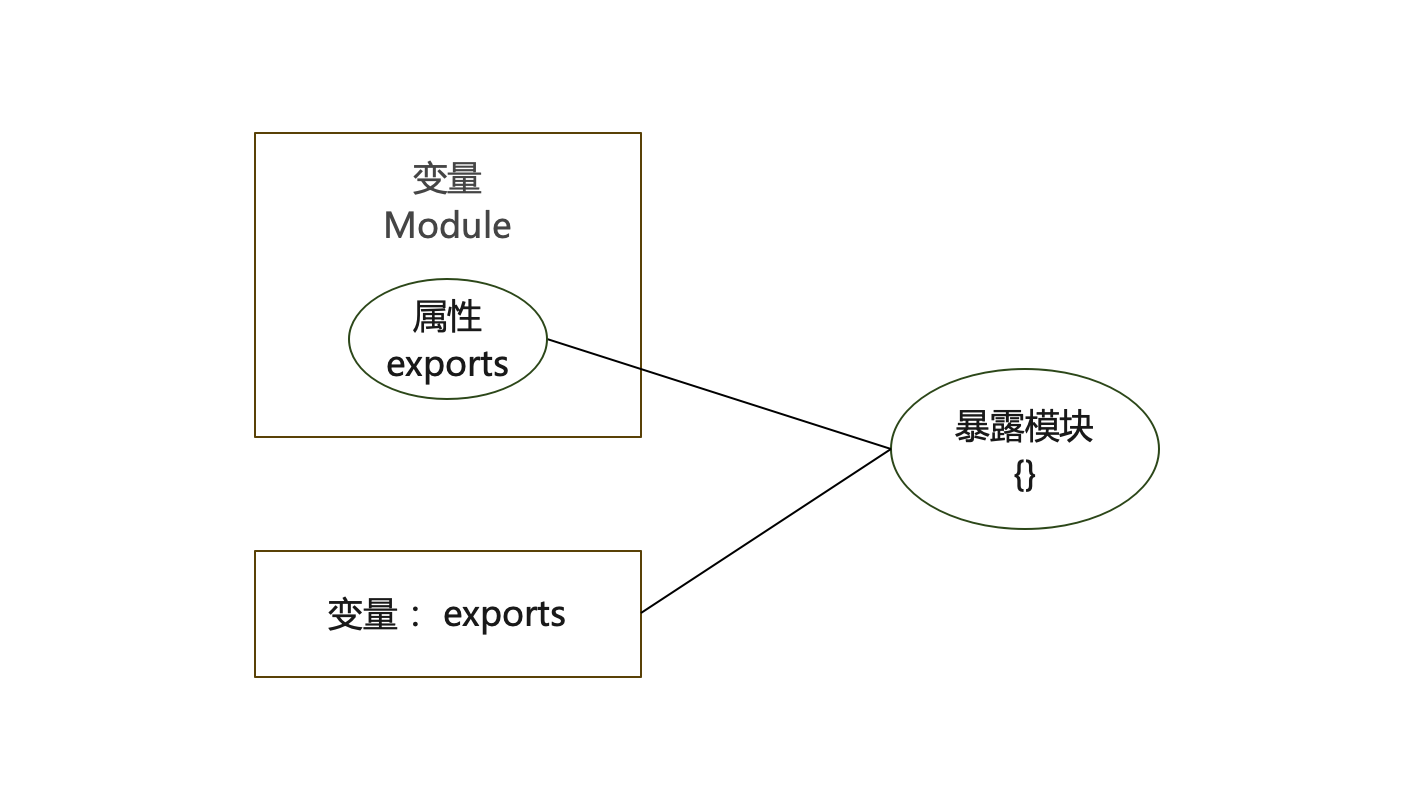
# exports/ module.exports 区别
- exports:首先对于本身来讲是一个变量(对象),它不是 module 的引用,它是{}的引用,它指向 module.exports 的{}模块
- module.exports:首先,module 是一个变量,指向一块内存,exports 是 module 中的一个属性,存储在内存中,然后 exports 属性指向{}模块
内存示意图:
 理想情况下:
理想情况下:
exports.bar=function(){};
module.exports.bar=function(){}
上述代码内存示意图:
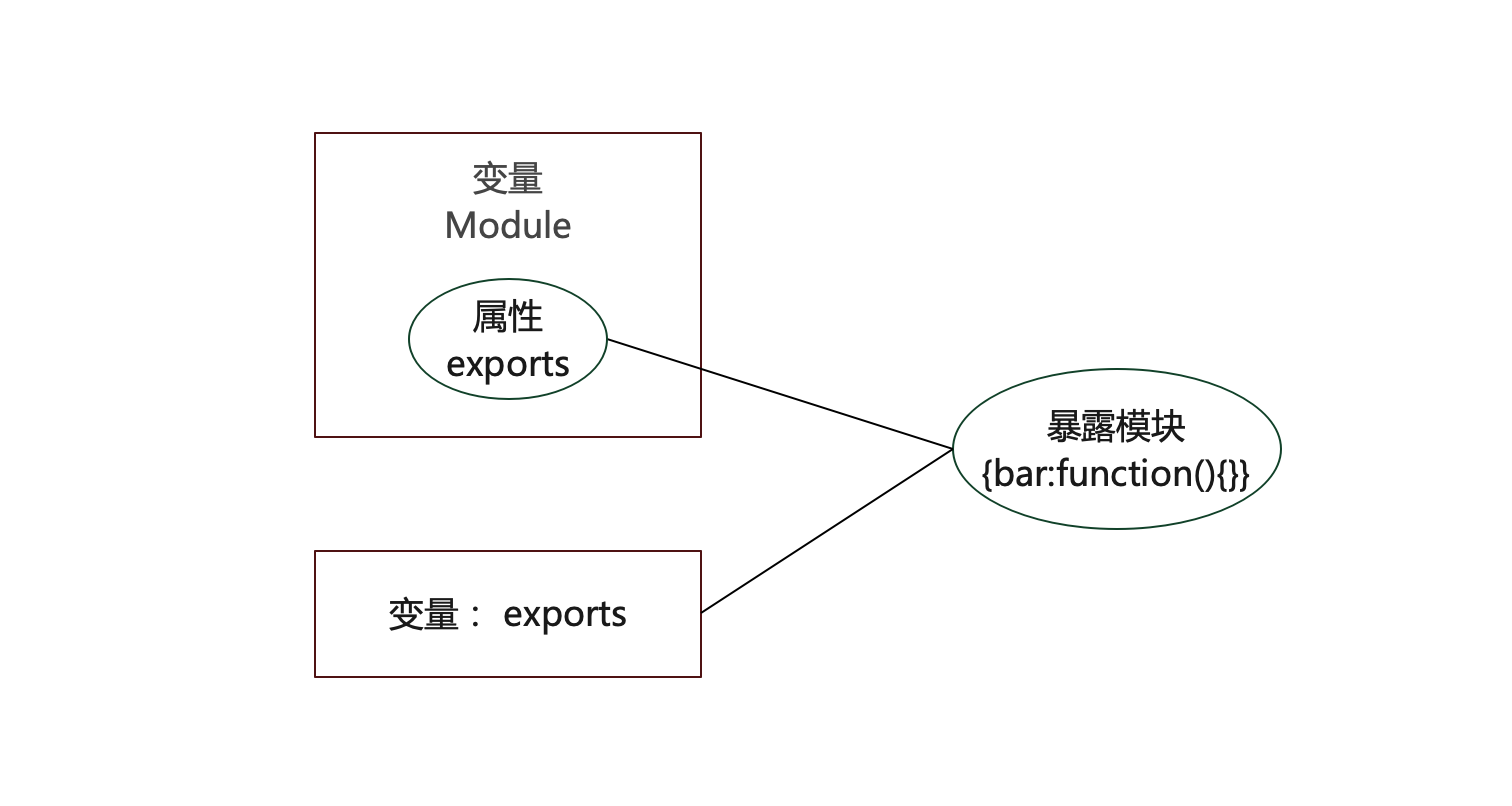 两个方式是等价的,因为他们改变的内存是暴露模块的{},操作同一块内存
两个方式是等价的,因为他们改变的内存是暴露模块的{},操作同一块内存
exports=function(){};
module.exports=function(){}
上述代码内存示意图:
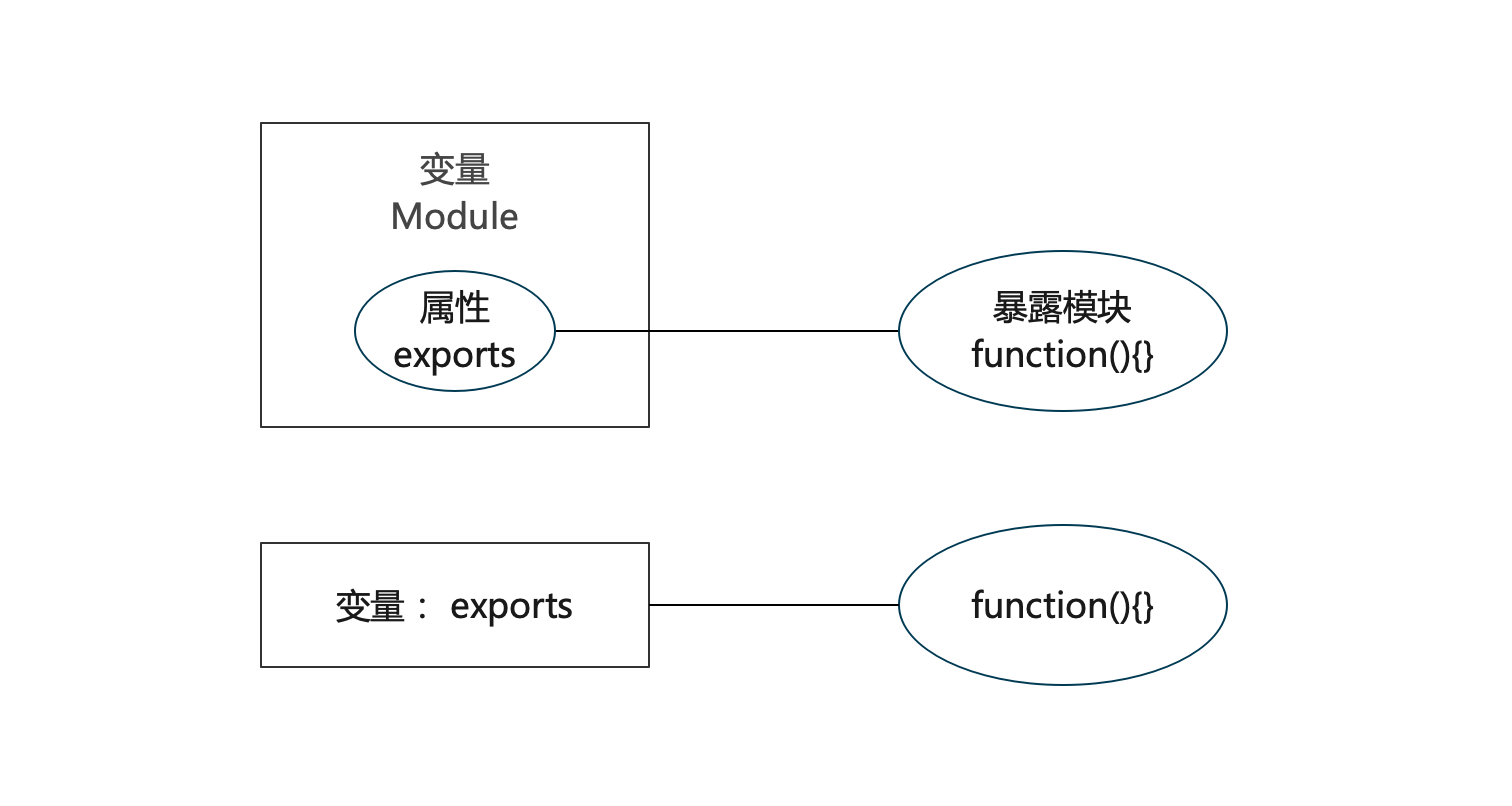
exports和module.exports操作的就不是同一块内存了,exports指向了新的内存,module.exports也指向了新的内存,但是nodejs中寻找的是module变量下的exports属性所指向的内存块,如果exports和module.exports操作的不是同一个内存块的话,exports就不起作用了。
通过 exports 只能使用.的方式来向外暴露内部变量,即:exports.xxx = xxx;module.exports 既可以通过.的形式,也可以直接赋值。即:module.exports.xxx = xxx;或者module.exports = {}
# c/c++模块编译
Node调用process.dlopen()方法进行加载和执行。在Node架构下,dlopen()方法在不同平台喜爱通过linvu兼容层进行了封装。
.node文件不需要编译,因为它是编写c/c++模块之后编译生成的,所以这里只有加载和执行过程。在执行过程中,模块的exports对象与.node模块产生联系,返回给调用者。
# JSON文件的编译
.json文件的编译时3种编译方式中最简单的。Node利用fs模块同步读取JSON文件的内容之后,调用JSON.parse()方法得到对象,然后将它赋值给模块对象的exports,供外部调用。
JSON文件在用作项目的配置文件时比较有用。如果我们定义了一个JSON配置,不需要调用fs模块去读取和解析,调用require() 引入即可。另外一层好处就是:模块缓存(文件模块),二次引入没有性能影响。
# 03. 核心模块
Node核心模块在编译成可执行文件的过程中被编译成了二进制文件。核心模块分为C/C++编写和JavaScript编写的两部分。 其中C/C++文件存在Node项目的src目录下哦啊,javascript文件存在lib目录下。
# JavaScript核心模块的编译过程
在编译所有C/C++文件之前,编译程序需要将所有的JavaScript 模块文件编译成C/C++代码。
- 转存为C/C++代码 Node采用V8附带的js2c.py 工具,将所有内置的JavaScript代码(src/nodejs 和lib/*.js)抓换成C++里面的数组,生成node_natives.h 头文件,相关代码如下:

在这个过程中,JavaScript代码以字符串的形式存储在node命名空间中,是不可执行的。在启动node进程中,JavaScript代码直接加载进内存中。在加载过程中,JavaScript核心模块经历标识符分析后直接定位到内存中,比普通的文件模块从磁盘中查找快很多。
- 编译JavaScript核心模块 lib目录下的所有模块文件没有定义require,module,exports这些变量。在引入JavaScript核心模块的过程中,经历了头尾包装的过程,然后执行和导出了exports对象。与文件模块有区别的地方在于:获取源代码的方式(核心模块是从内存中加载的)以及缓存执行结果的位置。
JavaScript核心模块的定义如下,源文件通过process.bind('natives')取出,编译成功的模块缓存到NativeModule._cache对象上,文件模块则缓存到Module._cache对象上。

# C/C++ 核心模块的编译过程
在核心模块中, 有些模块完全通过C/C++编写,有些则是C/C++完成核心部分,其他部分由JavaScript实现包装或向外导出,以满足性能需求。
由纯C/C++编写的模块统一称为内建模块, 因为它们通常不被用户直接调用。Node的buffer,crypto,evals, fs, os等模块都是通过部分C/C++编写的。
- 内建模块的组织形式
内建模块内部结构定义如下:
struct node_module_struct {
int version;
void *dso_handle;
const char *filename;
void (*register_func) (v8::Handle<v8::Object> target);
const char *modname;
};
每一个内建模块在定义之后,通过NODE_MODULE宏将模块定义到node命名空间中,模块的具体初始化方法挂载为结构D饿register_func 成员
#define NODE_MODULE(modname, regfunc)
extern "C" {
NODE_MODULE_EXPORT node::node_module_struct modname ## _module =
{
NODE_STANDARD_MODULE_STUFF,
regfunc,
NODE_STRINGIFY(modname)
};
}
node_extension.h文件将这些散列的内建模块统一放进了node_module_list的数组中,模块有
node_buffer
node_crypto
node_evals
node_fs
node_http_parser
node_os
node_zlib
node_timer_wrap
node_tcp_wrap
node_udp_wrap
node_pipe_wrap
node_cares_wrap
node_tty_wrap
node_process_wrap
node_fs_event_wrap
node_signal_watcher
Node通过get_builtin_module()方法从node_module_list数组中取出这些模块。
内建模块的优势在于:性能优于脚本语言;文件编译时,被编译进二进制文件。一旦Node执行,被直接加载进内存中,无须再次做标识符定位,文件定位,编译等过程,直接可执行。
- 内建模块的导出。 node的所有模块关系汇总,存在如图的一种依赖关系,即文件模块可能会依赖于核心模块,核心模块可能会依赖于内建模块。
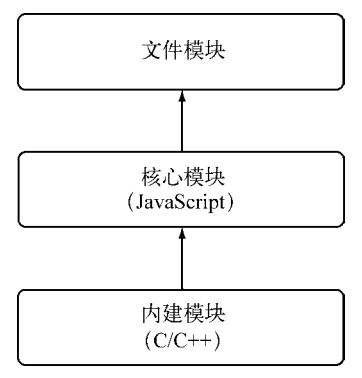
不推荐文件模块直接调用内建模块。如果需要。直接调用核心模块。因为核心模块基本都封装了内建模块。 内建模块通过什么将内部变量或者方法导出,以供外部JavaScript核心模块使用?
Node在启动时,会生成一个全局变量process,并提供Binding()方法协助加载内建模块。
Binding()的实现代码在src/node.cc中,具体如下:
static Handle<Value> Binding(const Arguments& args) {
HandleScope scope;
Local<String> module = args[0]->ToString();
String::Utf8Value module_v(module);
node_module_struct* modp;
if (binding_cache.IsEmpty()) {
binding_cache = Persistent<Object>::New(Object::New());
}
Local<Object> exports;
if (binding_cache->Has(module)) {
exports = binding_cache->Get(module)->ToObject();
return scope.Close(exports);
}
// Append a string to process.moduleLoadList
char buf[1024];
snprintf(buf, 1024, "Binding s", *module_v); %
uint32_t l = module_load_list->Length();
module_load_list->Set(l, String::New(buf));
if ((modp = get_builtin_module(*module_v)) != NULL) {
exports = Object::New();
modp->register_func(exports);
binding_cache->Set(module, exports);
} else if (!strcmp(*module_v, "constants")) {
exports = Object::New();
DefineConstants(exports);
binding_cache->Set(module, exports);
#ifdef __POSIX__
} else if (!strcmp(*module_v, "io_watcher")) {
exports = Object::New();
IOWatcher::Initialize(exports);
binding_cache->Set(module, exports);
#endif
} else if (!strcmp(*module_v, "natives")) {
exports = Object::New();
DefineJavaScript(exports);
binding_cache->Set(module, exports);
} else {
return ThrowException(Exception::Error(String::New("No such module")));
}
return scope.Close(exports);
}
在加载内建模块时,先创建一个exports对象,然后调用 get_builtin_module()方法取出内建模块兑现,通过执行register_func()填充 exports 对象,最后将exports对象按模块名缓存,并返回给调用方完成导出。
前面提到的JavaScript核心文件转换为C/C++数组存储后,通过process.bing('native')取出放置在NativeModule._source中
NativeModule._source = process.binding('natives');
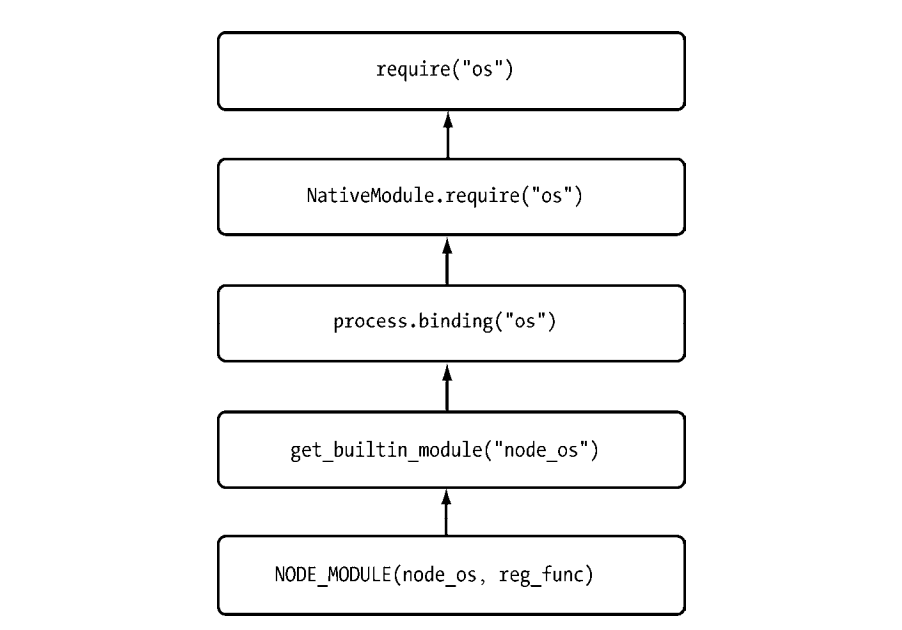
# 核心模块的引入流程
os模块的引入流程:
经历C/C++模块的内建模块定义,(JavaScript)核心模块的定义和引入以及文件模块层面的引入。
# 04. 模块调用栈
各个模块的调用关系: C/C++模块属于最底层的模块,属于核心模块,主要提供API给JavaScript核心模块和第三方JavaScript文件模块调用。
JavaScript核心模块主要扮演的指责有两类,一类是作为C/C++内建模块的封装层和桥接层,供文件调用。另外一类就是纯粹的功能模块,不需要于底层打交道。

# 05. 包与NPM
Node组织自身的核心模块,也使得第三方文件模块有序的编写和使用。在第三方模块中,模块与模块之间散列在各地,相互之间不能引用。在模块之外,包与NPM是将模块连接起来的一种机制。
包组织模块示意图:
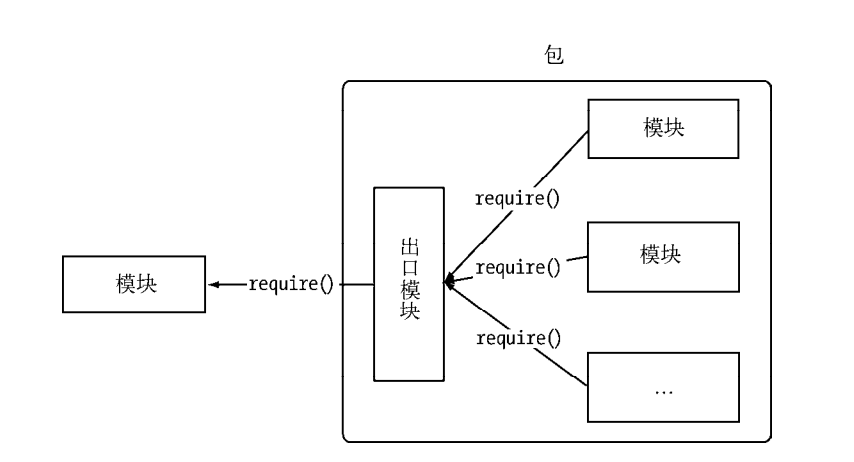
CommonJs的包规范定义:
- 包结构:用于组织包中的各种文件
- 包描述文件:用于描述包的相关信息,以供外部读取分析。
# 包结构
package.json: 包描述文件。
bin: 用于存放可执行二进制文件的目录。
lib: 用于存放JavaScript的目录。
doc:用于存放文档的目录。
test:用于存放测试的目录。
# 包描述文件与NPM
包描述文件(package.json)。 CommonJS为package.json文件定义了一些必需字段:
- name: 包名。规范定义它需要由小写的字母和数字组成,可以包含.、_和-,但是不允许出现空格。NPM建议不要在包名中附带node或js来重复标识它是JavaScript还是node】模块/
- description:包简介。
- version:版本号,一个语义话的版本号。(http://semver.org/上有详细定义)
- keywords:关键词数组,npm主要用来做分类搜索。
- maintainers: 包维护者列表。每个维护者由name、email֖web这3个属性组成。示例如下:"maintainers": [{ "name": "Jackson Tian", "email": "shyvo1987@gmail.com", "web": "http://html5ify. com" }]。 npm通过该属性进行权限验证。
- contributors: 贡献者列表
- bugs:一个可以反馈bug的网页地址或者邮件地址。
- licenses:当前包所使用的许可证列表,表示这个包在哪些许可证下使用。
"licenses": [{ "type": "GPLv2", "url": "http://www.example.com/licenses/gpl.html", }] - repositories。托管源代码的位置列表。
- dependencies。使用当前包需要依赖的包列表。
- homepage。当前包的网站地址。
- os:操作系统支持列表。这些操作系统的取值包括aix、freebsd、linux、macos、solaris、 vxworks、windows。如果设置列表为空,则不对操作系统做任何假设。
- cpu: CPU架构的支持列表。,有效的结构有arm、mips、ppc、sparc、x86֖x86_64。Վ os一样,如果设置列表为空,则不对操作系统做任何假设。
- engine: 支持的JavaScript引擎列表,有效的引擎取值包括ejs、flusspferd、gpsee、jsc、 spidermonkey、narwhal、node֖和v8。
- builtin:标志当前包是否内建在底层系统的标准组件
- direstories:包目录说明
- implements: 实现规范的列表。标志当前包实现了CommonJs的哪些规范。
- scripts:脚本说明对象。主要被包管理器用来安装,编译,测试和卸载包
在包描述文件的规范中,,NPM实际需要的字段有name、version、description、keywords、 repositories、author、bin、main、scripts、engines、dependencies、devDependencies。 与包规范区别的在于多了author、bin、main֖和devDependencies。
- auther:包作者
- bin:一些包作者可以包可以作为命名行工具使用。配置好bin字段后,通过npm install package_name -g 命名可以将脚本添加进执行路径中。
- main:模块引入require()在引入包时,会优先检查这个字段,将其作为包中其余模块的入口。如果不存在这个字段,require()方法会查找包目录下的index.js,index.json,index.node文件作为默认入口
- devDependencies:一些模块只在开发中需要依赖。
{
"name": "express",
"description": "Sinatra inspired web development framework",
"version": "3.3.4",
"author": "TJ Holowaychuk <tj@vision-media.ca>",
"contributors": [
{
"name": "TJ Holowaychuk",
"email": "tj@vision-media.ca"
},
{
"name": "Aaron Heckmann",
"email": "aaron.heckmann+github@gmail.com"
},
{
"name": "Ciaran Jessup",
"email": "ciaranj@gmail.com"
},
{
"name": "Guillermo Rauch",
"email": "rauchg@gmail.com"
}
],
"dependencies": {
"connect": "2.8.4",
"commander": "1.2.0",
"range-parser": "0.0.4",
"mkdirp": "0.3.5",
"cookie": "0.1.0",
"buffer-crc32": "0.2.1",
"fresh": "0.1.0",
"methods": "0.0.1",
"send": "0.1.3",
"cookie-signature": "1.0.1",
"debug": "*"
},
"devDependencies": {
"ejs": "*",
"mocha": "*",
"jade": "0.30.0",
"hjs": "*",
"stylus": "*",
"should": "*",
"connect-redis": "*",
"marked": "*",
"supertest": "0.6.0"
},
"keywords": [
"express",
"framework",
"sinatra",
"web",
"rest",
"restful",
"router",
"app",
"api"
],
"repository": "git://github.com/visionmedia/express",
"main": "index",
"bin": {
"express": "./bin/express"
},
"scripts": {
"prepublish": "npm prune",
"test": "make test"
},
"engines": {
"node": "*"
}
}
# 局域NPM
在企业的内部应用中使用NPM与开源社区中使用有一定的差别。企业的限制在干,一方面需要享受到模块开发带来的低耦合和项目组织上的好处,另一方面却要考虑到模块保密性的问题。所以,通过NPM共享和发布存在潜在的风险。
为了同时能够享受到NPM上众多的包,同时对自己的包进行保密和限制,现有的解决方案就是企业搭建自己的NPM仓库。
企业局域NPM可以选择不同步官方源仓库中的包。
企业中混合使用官方仓库和局域仓库的示意图
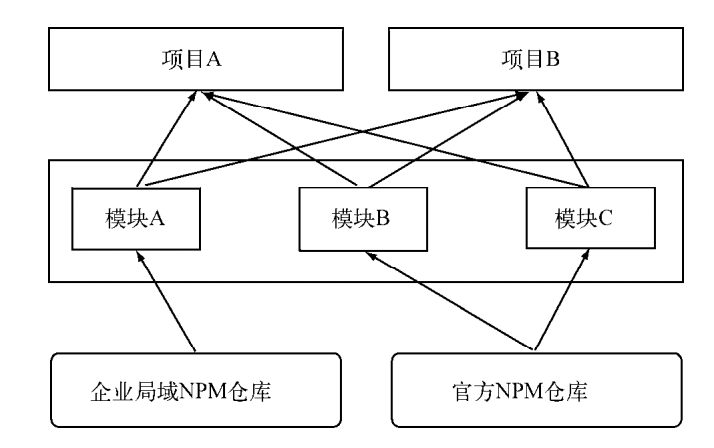
对于企业内部而言,私有的可重用模块可以打包到局域NPM仓库中,这样可以保持更新的中心化,不至于让各个小项目各自维护相同功能的模块,杜绝通过复制粘贴实现代码共享的行为。
# 06. 前后端共用模块
JavaScript 在 Node 出现之后,比别的编程语言多了一项优势,那就是一些模块可以在前后端实现共用,这是因为很多 API 在各个宿主环境下都提供。但是在实际情况中,前后端的环境是略有差别的。
# 模块的侧重点
前后端 JavaScript 分别搁置在 HTTP 的两端,它们扮演的角色并不同。浏览器端的 JavaScript 需要经历从同一个服务器端分发到多个客户端执行,而服务器端 JavaScript 则是相同的代码需要多次执行。前者的瓶颈在于带宽,后者的瓶颈则在于 CPU 和内存等资源。前者需要通过网络加载代码,后者从磁盘中加载,两者的加载速度不在一个数量级上。
纵观 Node 的模块引人过程,几乎全都是同步的。尽管与 Node 强调异步的行为有些相反,但它是合理的。但是如果前端模块也采用同步的方式来引人,那将会在用户体验上造成很大的问题。 UI 在初始化过程中需要花费很多时间来等待脚本加载完成。
鉴于网络的原因, commonJS 为后端 JavaScript 制定的规范并不完全适合前端的应用场景。经过一段争执之后, AMD 规范最终在前端应用场景中胜出。它的全称是 Asynchronous Module Definition ,即是“异步模块定义”,详见https://github.com/amdjs/amdjs-api/wiki/AMD。除此之外,还有玉伯定义的 CMD 规范。
# AMD 规范
AMD规范是CommonJs模块规范的延伸。模块定义如下:
define(id?, dependencies?, factory);
它的模块id与依赖是可选的,与Node模块相似的地方在于factory的内容就是实际代码的内容。
define(function() {
var exports = {};
exportes.sayHello = function() {
alert('Hello from module:'+ module.id);
};
return exportes;
})
- 区别-: 在于AMD是需要define明确定义一个模块,而Node实现是隐式的。目前是为了作用域隔离,仅在需求的时候被引入。避免变量污染和不小心被修改。
- 区别二:内容需要通过返回的方式实现导出。
# CMD规范
与AMD的主要区别在于定义模块和依赖引入的部分。AMD需要在声明模块的时候指定所有依赖,通过形参传递给依赖到模块内容中。
define(['dep1','dep2'], function(dep1, dep2){
return function(){}
});
与AMD模块规范相比,CMD模块更接近于Node对CommonJS规范的定义
define(factory)
在依赖部分,CMD支持动态引入
define(function(require, exports, module){
// the module code goes here
})
require,exports和module通过形参传递给模块,需要时,通过require()引入。
# 兼容多种模块规范
兼容Node,AMD,CMD,以及常见的浏览器
;(function (name, definition) {
// 检测上ူ文环境是否为AMDईCMD
var hasDefine = typeof define === 'function',
// 检查上ူ文环境是否为Node
hasExports = typeof module !== 'undefined' && module.exports;
if (hasDefine) {
// AMD环境ईCMD环境
define(definition);
} else if (hasExports) {
// 定义为通Node模块
module.exports = definition();
} else {
// 将模块的执行结ࡕࠬ在windowՎ量中Lj在៓બ器中thisኸၠwindow对象
this[name] = definition();
}
})('hello', function () {
var hello = function () {};
retur