
 理解Buffer
理解Buffer
JavaScript对于字符串(string)的操作十分友好,无论是宽字节字符串还是单字节字符串, 都被认为是一个字符串。示例代码如下所示:
console.log("0123456789".length); // 10
console.log("零一二三四五六七八九".length); //10
console.log("\u00bd".length); // 1
# 01. Buffer 结构
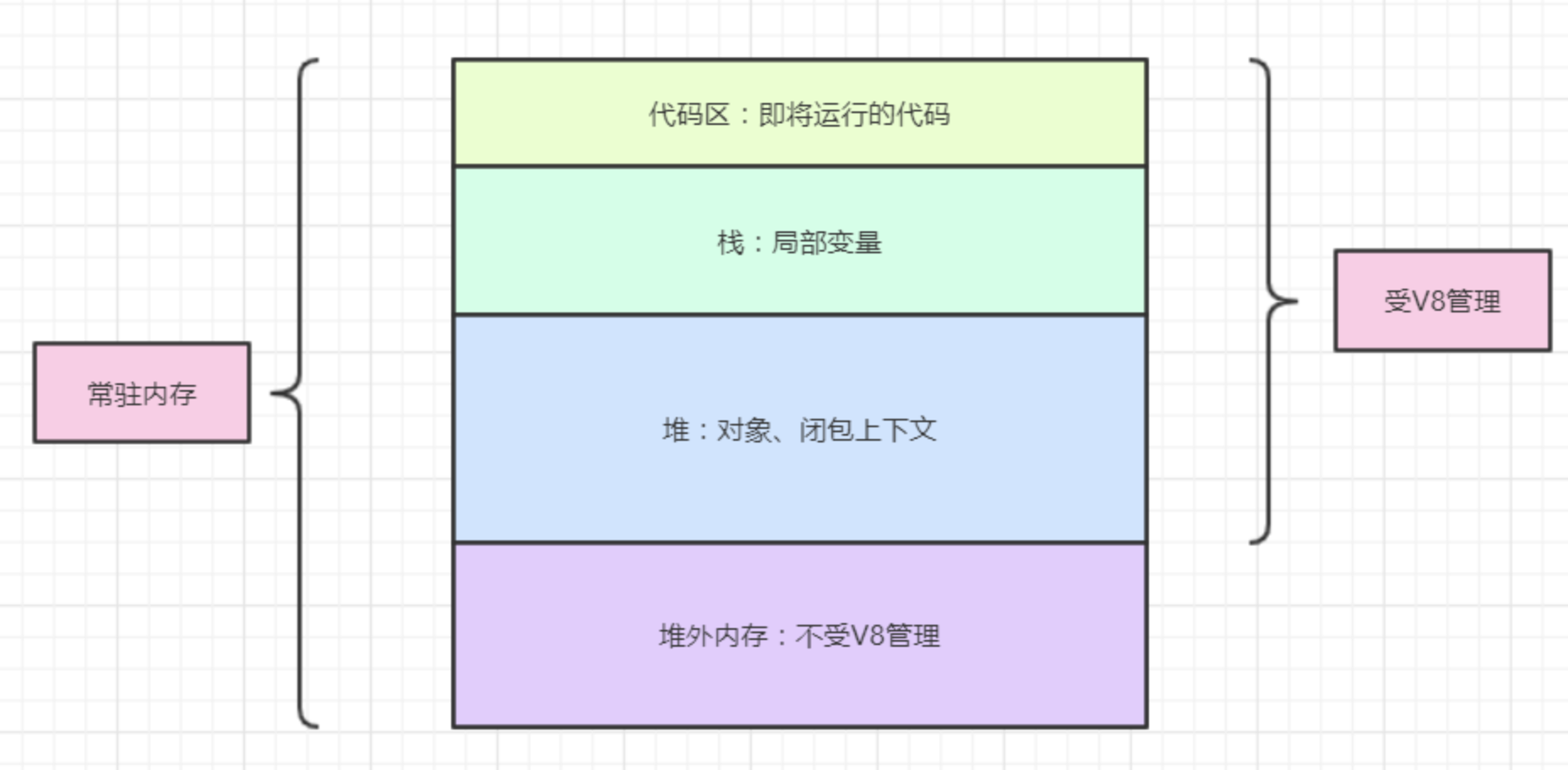
Buffer是一个像Array的对象,但它主要用于操作字节。
# 模块结构
Buffer是一个典型的JavaScript与C++结合的模块,它将性能相关部分用C++实现,将非性能相关的部分用JavaScript实现.
Buffer的分工 如图所示。

Buffer所占用的内存不是通过V8分配的,属于堆外内存。由于V8垃圾回收性能的影响,将常用的操作对象用更高效和专有的内存分配回收策略来管理是个不错的思路。由于Buffer太过常见,Node在进程启动时就已经加载了它,并将其放在全局对象(global)
上。所以在使用Buffer时,无须通过require()即可直接使用。
# Buffer对象 (opens new window)
提示
在v6.0之前创建Buffer对象直接使用new Buffer()构造函数来创建对象实例,但是Buffer对内存的权限操作相比很大,可以直接捕获一些敏感信息,所以在v6.0以后,官方文档里面建议使用 Buffer.from() 接口去创建Buffer对象。
Buffer对象类似于数组,它的元素为16进制的两位数,即0到255的数值。
var str = "深入浅出node.js";
var buf = Buffer.from(str, 'utf8');
console.log(buf);
// => <Buffer e6 b7 b1 e5 85 a5 e6 b5 85 e5 87 ba 6e 6f 64 65 2e 6a 73>
由上面的示例可见,不同编码的字符串占用的元素个数各不相同,上面代码中的中文字在UTF8编码下占用3个元素,字母和半角标点符号占用1个元素。
# Buffer内存分配
Buffer对象的内存分配不是在V8的堆内存中,而是在Node的C++层面实现内存的申请的。因为处理大量的字节数据不能采用需要一点内存就向操作系统申请一点内存的方式,这可能造成大量的内存申请的系统调用,对操作系统有一定压力。为此Node在内存的使用上应用的是在C++层面申请内存、在JavaScript中分配内存的策略。
为了高效地使用申请来的内存,Node采用了slab分配机制。slab是一种动态内存管理机制。
slab就是一块申请好的固定大小的内存区域。slab具有如下3种状态。
full:完全分配状态。
partial:部分分配状态。
empty:没有被分配状态。
当我们需要一个Buffer对象,可以通过以下方式分配指定大小的Buffer对象:
Buffer.alloc(size)
Node以8 KB为界限来区分Buffer是大对象还是小对象:
Buffer结构:
[Function: Buffer] {
poolSize: 8192,
from: [Function: from],
of: [Function: of],
alloc: [Function: alloc],
allocUnsafe: [Function: allocUnsafe],
allocUnsafeSlow: [Function: allocUnsafeSlow],
isBuffer: [Function: isBuffer],
compare: [Function: compare],
isEncoding: [Function: isEncoding],
concat: [Function: concat],
byteLength: [Function: byteLength],
[Symbol(kIsEncodingSymbol)]: [Function: isEncoding]
}
Buffer.poolSize = 8 * 1024; 这个8 KB的值也就是每个slab的大小值,在JavaScript层面,以它作为单位单元进行内存的分配。 加载时调用 createPool() 相当于初始化了一个 8kb 的内存空间,这样第一次内存分配也会变得高效,初始化的同时还用偏移量 poolOffset 来记录使用了多少字节
buffer.poolSize = 8 * 1024;
let poolSize, poolOffset, allocPool;
... // 中间代码省略
function createPool() {
poolSize = Buffer.poolSize;
allocPool = createUnsafeArrayBuffer(poolSize);
setHiddenValue(allocPool, arraybuffer_untransferable_private_symbol, true);
poolOffset = 0;
}
createPool();
分配小Buffer对象
如果指定Buffer的大小少于8 KB,Node会按照小对象的方式进行分配。Buffer的分配过程中主要使用一个局部变量pool作为中间处理对象,处于分配状态的slab单元都指向它。以下是分配一个全新的slab单元的操作,它会将新申请的SlowBuffer对象指向它:
var pool;
function allocPool() {
pool = new SlowBuffer(Buffer.poolSize);
pool.used = 0;
}
新构造的slab单元示例:slab处于empty状态:

这次构造将会去检查pool对象,如果pool没有被创建,将会创建一个新的slab单元指向它:
if (!pool || pool.length - pool.used < this.length) allocPool();
同时当前Buffer对象的parent属性指向该slab,并记录下是从这个slab的哪个位置(offset)开始使用的,slab对象自身也记录被使用了多少字节,代码如下:
this.parent = pool;
this.offset = pool.used;
pool.used += this.length;
if (pool.used & 7) pool.used = (pool.used + 8) & ~7;
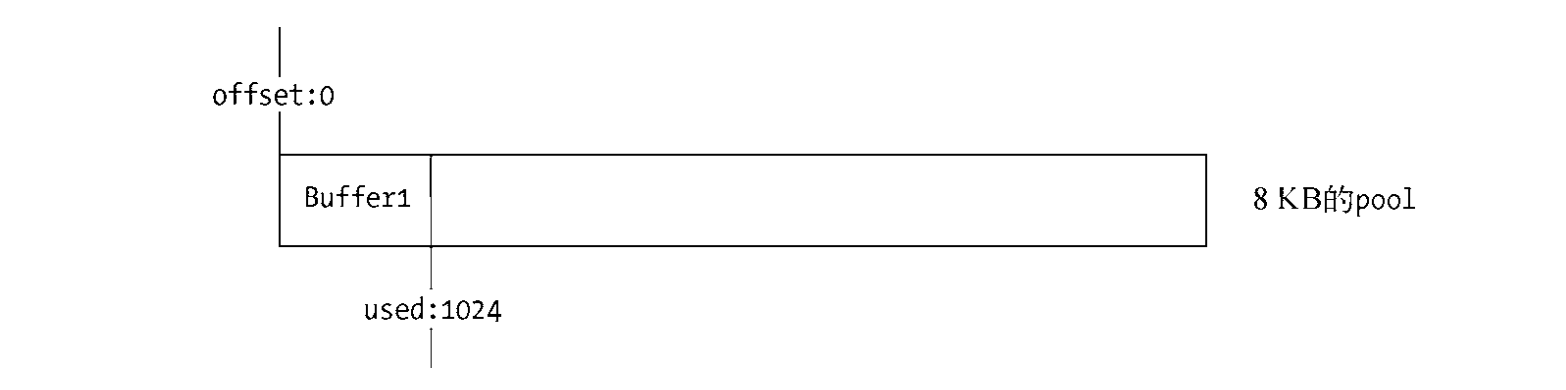
构造小Buffer对象时的代码如下: Buffer.alloc(1024) 从一个新的slab单元中初次分配一个Buffer对象: slab状态为partial
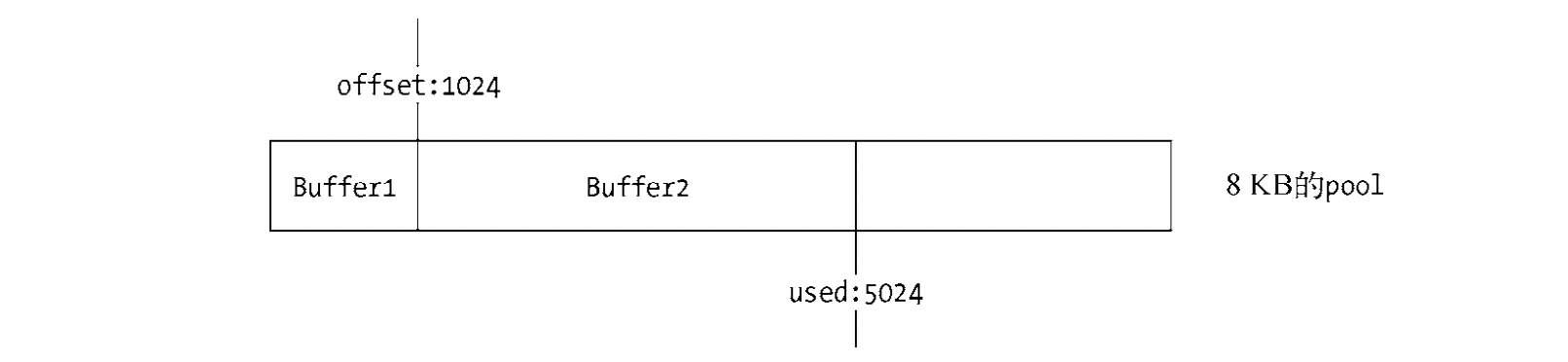
当再次创建一个Buffer对象时,构造过程中将会判断这个slab的剩余空间是否足够。如果足 够,使用剩余空间,并更新slab的分配状态。下面的代码创建了一个新的Buffer对象,它会引起 一次slab分配:
构造小Buffer对象时的代码如下: Buffer.alloc(4000)
从slab单元中再次分配一个Buffer对象:
在一个小对象分配之前会判断这个 pool 空间是否还够,如果不够的话就会重新申请一块新的8KB内存来分配。
所以一块 slab 可以被多个对象占有,加入第一次分配了1KB,但是下一个内存则要8KB,那么就造成了内存的浪费。这个1KB的小对象就占据了一整块内存。而且内存的释放规则是所有的对象释放之后,这块8KB的slab才会回收.
大对象内存分配
如果这个对象是超过了 slab 的大小,那么就不会占用slab块,直接使用C++层面分配你所需要的大小,这块空间就会被你一直占有。
// Big buffer, just alloc one
this.parent = new SlowBuffer(this.length);
this.offset = 0;
# 02. Buffer转换
Node.js 目前支持的字符编码包括:
- ascii - 仅支持 7 位 ASCII 数据。如果设置去掉高位的话,这种编码是非常快的。
- utf8 - 多字节编码的 Unicode 字符。许多网页和其他文档格式都使用 UTF-8 。
- utf16le - 2 或 4 个字节,小字节序编码的 Unicode 字符。支持代理对(U+10000 至 U+10FFFF)。
- ucs2 - utf16le 的别名。
- base64 - Base64 编码。
- latin1 - 一种把 Buffer 编码成一字节编码的字符串的方式。
- binary - latin1 的别名。
- hex - 将每个字节编码为两个十六进制字符
- 创建 Buffer 类
Buffer 提供了以下 API 来创建 Buffer 类:
Buffer.alloc(size[, fill[, encoding]]): 返回一个指定大小的 Buffer 实例,如果没有设置 fill,则默认填满 0
Buffer.allocUnsafe(size): 返回一个指定大小的 Buffer 实例,但是它不会被初始化,所以它可能包含敏感的数据
Buffer.allocUnsafeSlow(size)
Buffer.from(array): 返回一个被 array 的值初始化的新的 Buffer 实例(传入的 array 的元素只能是数字,不然就会自动被 0 覆盖)
Buffer.from(arrayBuffer[, byteOffset[, length]]): 返回一个新建的与给定的 ArrayBuffer 共享同一内存的 Buffer。
Buffer.from(buffer): 复制传入的 Buffer 实例的数据,并返回一个新的 Buffer 实例
Buffer.from(string[, encoding]): 返回一个被 string 的值初始化的新的 Buffer 实例
- 写入缓冲区 写入 Node 缓冲区的语法如下所示:
buf.write(string[, offset[, length]][, encoding])
参数描述如下:
string - 写入缓冲区的字符串。
offset - 缓冲区开始写入的索引值,默认为 0 。
length - 写入的字节数,默认为 buffer.length
encoding - 使用的编码。默认为 'utf8' 。
返回值: 返回实际写入的大小。如果 buffer 空间不足, 则只会写入部分字符串。
实例
buf = Buffer.alloc(256);
len = buf.write("www.runoob.com");
console.log("写入字节数 : "+ len);
- 从缓冲区读取数据 读取 Node 缓冲区数据的语法如下所示:
buf.toString([encoding[, start[, end]]])
参数描述如下:
encoding - 使用的编码。默认为 'utf8' 。
start - 指定开始读取的索引位置,默认为 0。
end - 结束位置,默认为缓冲区的末尾。
返回值: 解码缓冲区数据并使用指定的编码返回字符串。
buf = Buffer.alloc(26);
for (var i = 0 ; i < 26 ; i++) {
buf[i] = i + 97;
}
console.log( buf.toString('ascii')); // 输出: abcdefghijklmnopqrstuvwxyz
console.log( buf.toString('ascii',0,5)); //使用 'ascii' 编码, 并输出: abcde
console.log( buf.toString('utf8',0,5)); // 使用 'utf8' 编码, 并输出: abcde
console.log( buf.toString(undefined,0,5)); // 使用默认的 'utf8' 编码, 并输出: abcde
// 输出结果为:
abcdefghijklmnopqrstuvwxyz
abcde
abcde
abcde
- Buffer 转换为 JSON 对象
将 Node Buffer 转换为 JSON 对象的函数语法格式如下:
buf.toJSON()
const buf = Buffer.from([0x1, 0x2, 0x3, 0x4, 0x5]);
const json = JSON.stringify(buf);
// 输出: {"type":"Buffer","data":[1,2,3,4,5]}
console.log(json);
const copy = JSON.parse(json, (key, value) => {
return value && value.type === 'Buffer' ?
Buffer.from(value.data) :
value;
});
// 输出: <Buffer 01 02 03 04 05>
console.log(copy);
// 输出结果为:
{"type":"Buffer","data":[1,2,3,4,5]}
<Buffer 01 02 03 04 05>
# Buffer 的拼接
Buffer在使用场景中,通常是以一段一段的方式传输。以下是常见的从输入流中读取内容的 示例代码:
var fs = require('fs');
var rs = fs.createReadStream('test.md');
var data = '';
// data事件中获取的chunk对象即是Buffer对象。
rs.on("data", function (chunk){
data += chunk; // =》 data = data.toString() + chunk.toString();
});
rs.on("end", function () {
console.log(data);
});
外国人的语境通常是指英文环境,在他们的场景下,这个toString()不会造成任何问题。但对于宽字节的中文,却会形成问题。为了重现这个问题,下面我们模拟近似的场景,将文件可读流的每次读取的Buffer长度限制为11,代码如下:
var rs = fs.createReadStream('test.md', {highWaterMark: 11});
输出:
窗前明��光
疑是地上霜
���头望明月
低头���故乡
# 乱码是如何产生的
上面的诗歌中,“月”、“是”、“望”、“低”4个字没有被正常输出,取而代之的是3个 。产生这个输出结果的原因在于文件可读流在读取时会逐个读取Buffer。这首诗的原始Buffer应存储为:
<Buffer e7 aa 97 e5 89 8d e6 98 8e e6 9c 88 e5 85 89 0a e7 96 91 e6 98 af e5 9c b0 e4 b8 8a e9 9c 9c 0a e4 b8 be e5 a4 b4 e6 9c 9b e6 98 8e e6 9c 88 0a e4 bd ... 13 more bytes>
们限定了Buffer对象的长度为11:
<Buffer e7 aa 97 e5 89 8d e6 98 8e e6 9c>
<Buffer 88 e5 85 89 2c e7 96 91 e6 98 af>
<Buffer e5 9c b0 e4 b8 8a e9 9c 9c 2c e4>
<Buffer b8 be e5 a4 b4 e6 9c 9b e6 98 8e>
<Buffer e6 9c 88 2c e4 bd 8e e5 a4 b4 e6>
<Buffer 80 9d e6 95 85 e4 b9 a1>
buf.toString()方法默认以UTF-8为编码,中文字在UTF-8下占3个字节。所以第一个Buffer对象在输出时,只能显示3个字符,Buffer中剩下的2个字节(e6 9c)将会以乱码的形式显示。第二个Buffer对象的第一个字节也不能形成文字,只能显示乱码。于是形成一些文字无法正常显示的问题。
# setEncoding()与string_decoder()
setEncoding(): 可读流设置编码
var rs = fs.createReadStream('test.md', { highWaterMark: 11});
rs.setEncoding('utf8');
// 输出:
床前明月光,疑是地上霜;举头望明月,低头思故乡
无论如何设置编码,触发data事件的次数依旧相同,这意味着设置编码并未改变按段读取的基本方式。
调用setEncoding()时,可读流对象在内部设置了一个decoder对象。每次data事件都通过该decoder对象进行Buffer到字符串的解码,然后传递给调用者。是故设置编码后,data不再收到原始的Buffer对象。但是这依旧无法解释为何设置编码后乱码问题被解决掉了。
decoder对象来自于string_decoder模块StringDecoder的实例对象。
var StringDecoder = require('string_decoder').StringDecoder;
var decoder = new StringDecoder('utf8');
var buf1 = new Buffer([0xE5, 0xBA, 0x8A, 0xE5, 0x89, 0x8D, 0xE6, 0x98, 0x8E, 0xE6, 0x9C]);
console.log(decoder.write(buf1));
// => 床前明
var buf2 = new Buffer([0x88, 0xE5, 0x85, 0x89, 0xEF, 0xBC, 0x8C, 0xE7, 0x96, 0x91, 0xE6]);
console.log(decoder.write(buf2));
// => 月光,疑
“月”字的前两个字节被保留在StringDecoder实例内部,第二次write()时,会将这2个剩余字节和后续11个字节组合在一起,再次用3的整数倍字节进行转码。
string_decoder的局限性: 只能处理UTF-8、Base64和UCS-2/UTF-16LE这3种编码。
# 正确拼接Buffer
var chunks = [];
var size = 0;
res.on('data', function (chunk) {
chunks.push(chunk);
size += chunk.length;
});
res.on('end', function () {
var buf = Buffer.concat(chunks, size);
var str = iconv.decode(buf, 'utf8');
console.log(str);
});
正确的拼接方式是用一个数组来存储接收到的所有Buffer片段并记录下所有片段的总长度,然后调用Buffer.concat()方法生成一个合并的Buffer对象
Buffer.concat = function(list, length) {
if (!Array.isArray(list)) {
throw new Error('Usage: Buffer.concat(list, [length])');
}
if (list.length === 0) {
return new Buffer(0);
} else if (list.length === 1) {
return list[0];
}
if (typeof length !== 'number') {
length = 0;
for (var i = 0; i < list.length; i++) {
var buf = list[i];
length += buf.length;
}
}
var buffer = new Buffer(length);
var pos = 0;
for (var i = 0; i < list.length; i++) {
var buf = list[i];
buf.copy(buffer, pos);
pos += buf.length;
}
return buffer;
};
# Buffer 与性能
在应用中,我们通常会操作字符串,但一旦在网络中传输,都需要转换为Buffer,以进行二进制数据传输。在Web应用中,字符串转换到Buffer是时时刻刻发生的,提高字符串到Buffer的转换效率,可以很大程度地提高网络吞吐率。
- 文件读取 Buffer的使用除了与字符串的转换有性能损耗外,在文件的读取时,有一个highWaterMark设置对性能的影响至关重要。 在fs.createReadStream(path, opts)时,我们可以传入一些参数,代码如下:
{
flags: 'r',
encoding: null,
fd: null,
mode: 0666,
highWaterMark: 64 * 1024
}
还可以传递start和end来指定读取文件的位置范围:
{start: 90, end: 99}
从这个Buffer中通过slice()方法取出部分数据作为一个小Buffer对象,再通过data事件传递给调用方。如果Buffer用完,则重新分配一个;如果还有剩余,则继续使用。下面为分配一个新的Buffer对象的操作:
var pool;
function allocNewPool(poolSize) {
pool = new Buffer(poolSize);
pool.used = 0;
}
Node源代码中分配新的Buffer对象的判断条件如下所示:
if (!pool || pool.length - pool.used < kMinPoolSpace) {
// discard the old pool
pool = null;
allocNewPool(this._readableState.highWaterMark);
}
这里与Buffer的内存分配比较类似,highWaterMark的大小对性能有两个影响的点。
- highWaterMark设置对Buffer内存的分配和使用有一定影响。
- highWaterMark设置过小,可能导致系统调用次数过多。
文件流读取基于Buffer分配,Buffer则基于SlowBuffer分配,这可以理解为两个维度的分配策 略。如果文件较小(小于8 KB),有可能造成slab未能完全使用。
由于fs.createReadStream()内部采用fs.read()实现,将会引起对磁盘的系统调用,对于大文件而言,highWaterMark的大小决定会触发系统调用和data事件的次数